
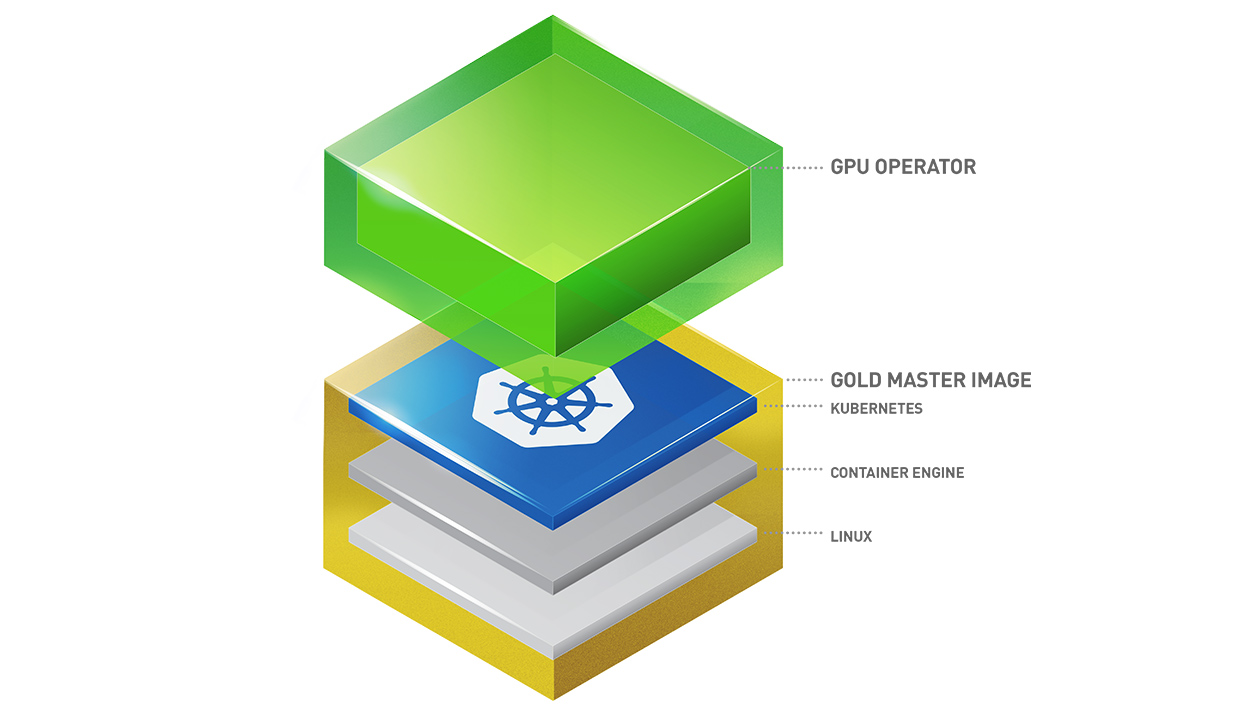
Kubernetes provides access to special hardware resources such as NVIDIA GPUs, NICs, Infiniband adapters and other devices through the device plugin framework. However, configuring and managing nodes with these hardware resources requires configuration of multiple software components such as drivers, container runtimes or other libraries which are difficult and prone to errors. The NVIDIA GPU Operator uses the operator framework within Kubernetes to automate the management of all NVIDIA software components needed to provision GPU. These components include the NVIDIA drivers (to enable CUDA), Kubernetes device plugin for GPUs, the NVIDIA Container Runtime, automatic node labelling, DCGM based monitoring and others.
The GPU Operator allows administrators of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster. Instead of provisioning a special OS image for GPU nodes, administrators can rely on a standard OS image for both CPU and GPU nodes and then rely on the GPU Operator to provision the required software components for GPUs.
Note that the GPU Operator is specifically useful for scenarios where the Kubernetes cluster needs to scale quickly - for example provisioning additional GPU nodes on the cloud or on-prem and managing the lifecycle of the underlying software components. Since the GPU Operator runs everything as containers including NVIDIA drivers, the administrators can easily swap various components - simply by starting or stopping containers.
The GPU Operator is not a good fit for scenarios when special OS images are already being provisioned in a GPU cluster (for example using NVIDIA DGX systems) or when using hybrid environments that use a combination of Kubernetes and Slurm for workload management.
- Pascal+ GPUs are supported (incl. Tesla V100 and T4)
- Container Platforms
- Kubernetes v1.13+
- Note that the Kubernetes community supports only the last three minor releases as of v1.17. Older releases may be supported through enterprise distributions of Kubernetes such as Red Hat OpenShift. See the prerequisites for enabling monitoring in Kubernetes releases before v1.16.
- Red Hat OpenShift 4.1, 4.2 and 4.3 using Red Hat Enterprise Linux CoreOS (RHCOS) and CRI-O container runtime
- Kubernetes v1.13+
- Helm v3 (v3.1.z)
- Docker CE 19.03.z
- Linux distributions
- Ubuntu 18.04.z LTS
- Note that the GA has been validated with the 4.15 LTS kernel. When using the HWE kernel (e.g. v5.3), there are additional prerequisites before deploying the operator.
- Red Hat Enterprise Linux CoreOS (RHCOS) for use with OpenShift
- Ubuntu 18.04.z LTS
- The GPU operator has been validated with the following NVIDIA components:
- NVIDIA Container Toolkit 1.0.5
- NVIDIA Kubernetes Device Plugin 1.0.0-beta4
- NVIDIA Tesla Driver 440 (Current release is 440.64.00. See driver release notes)
- NVIDIA DCGM 1.7.2
- Deployment Scenarios
- Bare-metal
- GPU passthrough virtualization
- Nodes must not be pre-configured with NVIDIA components (driver, container runtime, device plugin).
- If the HWE kernel is used with Ubuntu 18.04, then the nouveau driver for NVIDIA GPUs must be blacklisted before starting the GPU Operator. Follow the steps in this guide to blacklist the nouveau driver.
- Node Feature Discovery (NFD) is required on each node. By default, NFD master and worker are automatically deployed. If NFD is already running in the cluster prior to the deployment of the operator, follow this step:
# Set the variable nfd.enabled=false at the helm install step:
$ helm install --devel --set nfd.enabled=false nvidia/gpu-operator --wait --generate-name- See notes on NFD setup
- For monitoring in Kubernetes 1.13 and 1.14, enable the kubelet "KubeletPodResources" feature gate. From Kubernetes 1.15 onwards, its enabled by default.
$ echo -e "KUBELET_EXTRA_ARGS=--feature-gates=KubeletPodResources=true" | sudo tee /etc/default/kubeletFor installing the GPU Operator on clusters with Red Hat OpenShift 4.1, 4.2 and 4.3 using RHCOS worker nodes, follow this guide.
# Install Helm from the official installer script
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
$ chmod 700 get_helm.sh
$ ./get_helm.sh
# Add the NVIDIA repo:
$ helm repo add nvidia https://nvidia.github.io/gpu-operator
$ helm repo update
# Note that after running this command, NFD will be automatically deployed. If you have NFD already setup, follow the NFD instruction from the Prerequisites.
$ helm install --devel nvidia/gpu-operator --wait --generate-name
# To check the gpu-operator version
$ helm ls
# Check the status of the pods to ensure all the containers are running. A sample output is shown below in the cluster
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
gpu-operator-resources nvidia-container-toolkit-daemonset-fjgjt 1/1 Running 0 5m11s
gpu-operator-resources nvidia-dcgm-exporter-fzpwp 2/2 Running 0 2m36s
gpu-operator-resources nvidia-device-plugin-daemonset-8kd64 1/1 Running 0 2m51s
gpu-operator-resources nvidia-device-plugin-validation 0/1 Completed 0 2m47s
gpu-operator-resources nvidia-driver-daemonset-8nwcb 1/1 Running 0 5m4s
gpu-operator-resources nvidia-driver-validation 0/1 Completed 0 4m37s
gpu-operator gpu-operator-576bf567c7-c9z9g 1/1 Running 0 5m19s
kube-system calico-kube-controllers-6b9d4c8765-7w5pb 1/1 Running 0 12m
kube-system calico-node-scfwp 1/1 Running 0 12m
kube-system coredns-6955765f44-9zjk6 1/1 Running 0 12m
kube-system coredns-6955765f44-r8v7r 1/1 Running 0 12m
kube-system etcd-ip-172-31-82-11 1/1 Running 0 13m
kube-system kube-apiserver-ip-172-31-82-11 1/1 Running 0 13m
kube-system kube-controller-manager-ip-172-31-82-11 1/1 Running 0 13m
kube-system kube-proxy-qmplb 1/1 Running 0 12m
kube-system kube-scheduler-ip-172-31-82-11 1/1 Running 0 13m
node-feature-discovery nfd-master-z2mxn 1/1 Running 0 5m19s
node-feature-discovery nfd-worker-s62kd 1/1 Running 1 5m19s
$ helm delete <gpu-operator-name>
# Check if the operator got uninstalled properly
$ kubectl get pods -n gpu-operator-resources
No resources found.# Create a tensorflow notebook example
$ kubectl apply -f https://nvidia.github.io/gpu-operator/notebook-example.yml
# Grab the token from the pod once it is created
$ kubectl get pod tf-notebook
$ kubectl logs tf-notebook
...
[I 23:20:42.891 NotebookApp] jupyter_tensorboard extension loaded.
[I 23:20:42.926 NotebookApp] JupyterLab alpha preview extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
JupyterLab v0.24.1
Known labextensions:
[I 23:20:42.933 NotebookApp] Serving notebooks from local directory: /home/jovyan
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=MY_TOKEN
You can now access the notebook on http://localhost:30001/?token=MY_TOKEN# Check if the dcgm-exporter is successufully deployed
$ kubectl get pods -n gpu-operator-resources | grep dcgm
# Check gpu metrics locally
$ dcgm_pod_ip=$(kubectl get pods -n gpu-operator-resources -lapp=nvidia-dcgm-exporter -ojsonpath='{range .items[*]}{.metadata.name}{"\n"}{end}' -o wide | tail -n 1 | awk '{print $6}')
$ curl $dcgm_pod_ip:9400/metrics
# To scrape gpu metrics from Prometheus, add dcgm endpoint to Prometheus via a configmap
$ tee dcgmScrapeConfig.yaml <<EOF
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator-resources
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
EOF
# Deploy Prometheus
$ helm install --name prom-monitoring --set-file extraScrapeConfigs=./dcgmScrapeConfig.yaml stable/prometheus
# Alternatively, if you find your prometheus pod pending and get this error "no persistent volumes available...", disable persistentVolumes. [Refer this](https://stackoverflow.com/questions/47235014/why-prometheus-pod-pending-after-setup-it-by-helm-in-kubernetes-cluster-on-ranch).
$ helm install --name prom-monitoring --set-file extraScrapeConfigs=./dcgmScrapeConfig.yaml --set alertmanager.persistentVolume.enabled=false --set server.persistentVolume.enabled=false stable/prometheus
# To check the metrics in browser
$ kubectl port-forward $(kubectl get pods -lapp=prometheus -lcomponent=server -ojsonpath='{range .items[*]}{.metadata.name}{"\n"}{end}') 9090 &
# Open in browser http://localhost:9090
# Deploy Grafana
$ helm install --name grafana-gpu-dashboard stable/grafana
# Decode the admin user and password to login in the dashboard
$ kubectl get secret grafana-test -o jsonpath="{.data.admin-user}" | base64 --decode ; echo
$ kubectl get secret grafana-test -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
# To open dashboard in browser
$ kubectl port-forward $(kubectl get pods --namespace default -l "app=grafana,release=grafana-test" -o jsonpath="{.items[0].metadata.name}") 3000 &
# In browser: http://localhost:3000
# On AWS: ssh -L 3000:localhost:3000 -i YOUR_SECRET_KEY INSTANCE_NAME@PUBLIC_IP
# Login in the dashboard with the decoded credentials and add Prometheus datasource
# Get Promethues IP to add to the Grafana datasource
$ prom_server_ip=$(kubectl get pods -lapp=prometheus -lcomponent=server -ojsonpath='{range .items[*]}{.metadata.name}{"\n"}{end}' -o wide | tail -n 1 | awk '{print $6}')
# Check if Prometheus is reachable
$ curl $prom_server_ip:9090
# Import this GPU metrics dashboard from Grafana https://grafana.com/grafana/dashboards/11578- DCGM is now deployed as part of the GPU Operator on OpenShift 4.3.
- The operator CRD has been renamed to
ClusterPolicy. - The operator image is now based on UBI8.
- Helm chart has been refactored to fix issues and follow some best practices.
- Fixed an issue with the toolkit container which would setup the NVIDIA runtime under
/run/nvidiawith a symlink to/usr/local/nvidia. If a node was rebooted, this would prevent any containers from being run with Docker as the container runtime configured in/etc/docker/daemon.jsonwould not be available after reboot. - Fixed a race condition with the creation of the CRD and registration.
- Added support for Helm v3. Note that installing the GPU Operator using Helm v2 is no longer supported.
- Added support for Red Hat OpenShift 4 (4.1, 4.2 and 4.3) using Red Hat Enterprise Linux Core OS (RHCOS) and CRI-O runtime on GPU worker nodes.
- GPU Operator now deploys NVIDIA DCGM for GPU telemetry on Ubuntu 18.04 LTS
- The driver container now sets up the required dependencies on i2c and ipmi_msghandler modules.
- Fixed an issue with the validation steps (for the driver and device plugin) taking considerable time. Node provisioning times are now improved by 5x.
- The SRO custom resource definition is setup as part of the operator.
- Fixed an issue with the clean up of driver mount files when deleting the operator from the cluster. This issue used to require a reboot of the node, which is no longer required.
- After the removal of the GPU Operator, a restart of the Docker daemon is required as the default container runtime is setup to be the NVIDIA runtime. Run the following command:
$ sudo systemctl restart docker- GPU Operator will fail on nodes already setup with NVIDIA components (driver, runtime, device plugin). Support for better error handling will be added in a future release.
- The GPU Operator currently does not handle updates to the underlying software components (e.g. drivers) in an automated manner.
- This release of the operator does not support accessing images from private registries, which may be required for air-gapped deployments.
Read the document on contributions. You can contribute by opening a pull request.
Please open an issue on the GitHub project for any questions. Your feedback is appreciated.