A Text to SQL endpoint built on the Databricks Environment.
One of the most common Gen AI needs for corporations is text-to-sql. Most solutions attempt a generic one-size-fits-all solution - they look at technical metadata surrounding the tables available and generate SQL to fit the request.
This repo tackles the problem from a different angle. Instead of a generic solution, we build a contextualized one, using a company's DBSQL query history and specialized metadata surrounding their tables and columns. In addition, it uses fine tuning and a company's own query history of their database, letting the solution learn from actual usage.
The ultimate prompt that is passed to the LLM for inferences is inspired by this blog post. This solution emulates everything in that post except for sample records. (Sample records would require administrative read access to all tables and would significantly increase the latency of the solution.)
There are two main parts to this repo:
- The Pipeline to ingest and build all the resources that we need to create this solution.
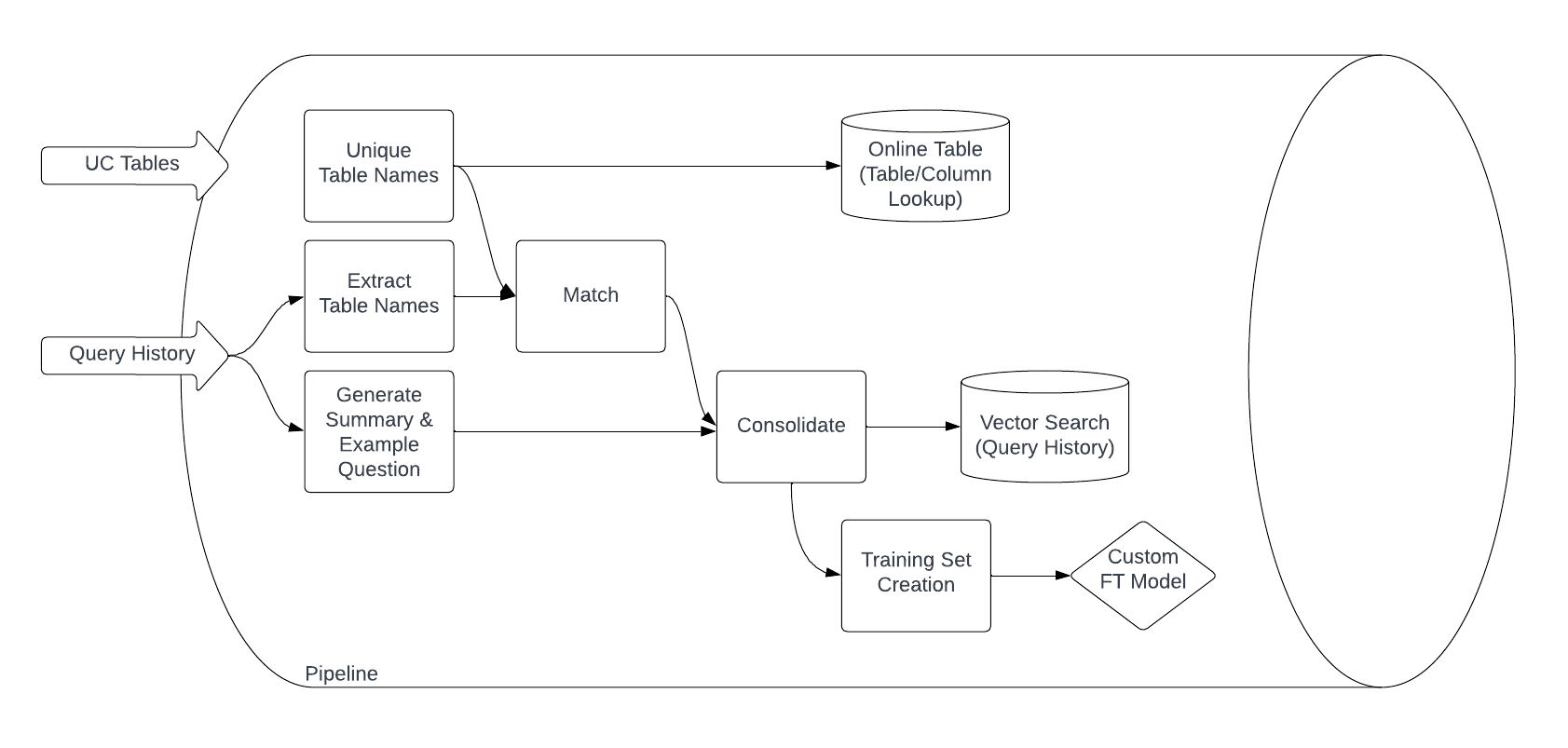
- The Model where we build various models to make use of these resources to create solutions.

Out of the box, this uses Databricks Query History and Unity Catalog Information Schema metadata from system tables, but there is no intrinsic need for the text-to-sql solution to be Databricks specific. It can source query history from any store and metadata from any catalog - users will need to customize the ingestion pipeline accordingly.
Note: See this issue. The Query History System table is in private preview and preparing to go public in mid-July - at this time there are no new customers being onboarded until then.
One of the benefits of using this solution is that it gets an organization comfortable with many Gen AI features inside Databricks, including:
- AI Functions (Public Preview)
- Vector Search
- Online Stores (Tables and Functions) (Public Preview)
- Model Serving
- Foundation Model Training (Gated Public Preview)
Lastly, and I can't stress this enough, but this is only meant as a starting point for organizations as they begin this journey. Chances are, this will not suffice as a standalone text-to-sql endpoint for their company out of the box, but it should be a huge help as they get started.