A Python implementation of the Go-Explore exploration algorithm without domain knowledge.
The setup for retro gym is more lengthy than the standard gym. gym comes preinstalled with many Atari environments, but retro allows you to import any ROM file you'd like. Follow the installation and usage procedures according to these links:
RetroMain Page (via OpenAI Website)RetroDocumentationGymMain Page (via OpenAI Website)GymDocumentation
- Try
threaded-atari.pyinstead ofatari.py, it's far faster when using multithreading
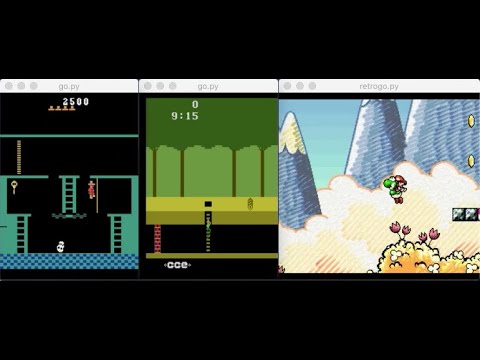
Click the image above to redirect to a 2-minute YouTube video. It shows a rendering of three environments with a random agent exploring, then returning to previously-discovered states according to the procedure of Go-Explore. These are obviously not samples of a trained agent, rather merely the random exploration agent after a bit of exploration.
- The logging and performance appears to match that of the official implementation written by the authors of the paper. On the left is the highscore reached thus far and on the right is the latest cell discovered. The agent has exploited a bug in the emulator that enables it to collect reward in the treasure room forever.

Looking back, there were far more efficient ways to accomplish this. Here are some ways in that I would write it differently in hindsight:
- For one, Python's built-in hash is far better for this purpose than anything from
hashlib. This is because Python'shash()function is fast and can hash the bytes of a numpy array usinghash(ndarray.tobytes()) - Some code refactoring made it much easier to read
- I realized that I partially messed up the cell function (it's supposed to be reduced to 8 possible values, I accidentally made it 32)
- Using a
defaultdictobject made it easier to automatically create a new cell if one is found, and attempted to be accessed before having been encountered in prior. - There were a few other components of the algorithm's logic that I misinterpreted in the initial implementation, but resolved in the latest version.
Taking these points into account, I've added v2 implementations which produce better results, for they are a more complete algorithm of the algorithm.
Here's a summary of the results observed in one particular run of threaded-atari-v2.py on MontezumaRevengeDeterministic-v4 (not cherry-picked):
Iterations: 0, Cells: 0, Frames: 0, Max Reward: 0
Iterations: 4184, Cells: 226, Frames: 68537, Max Reward: 100
Iterations: 10437, Cells: 582, Frames: 182623, Max Reward: 400
Iterations: 11814, Cells: 1183, Frames: 214587, Max Reward: 500
Iterations: 13176, Cells: 1261, Frames: 244967, Max Reward: 2500
Iterations: 102822, Cells: 3788, Frames: 2250169, Max Reward: 2600
Iterations: 163037, Cells: 4325, Frames: 3689907, Max Reward: 3600
Iterations: 267517, Cells: 4610, Frames: 6138934, Max Reward: 3900
Iterations: 381069, Cells: 4745, Frames: 8804395, Max Reward: 4900
Iterations: 404446, Cells: 4860, Frames: 9350689, Max Reward: 5100
Iterations: 645493, Cells: 5026, Frames: 14911490, Max Reward: 6100
Iterations: 882479, Cells: 5122, Frames: 20315900, Max Reward: 7100
Iterations: 3157501, Cells: 6637, Frames: 70733548, Max Reward: 7500
Iterations: 3611170, Cells: 6971, Frames: 80542377, Max Reward: 8300
Iterations: 3616284, Cells: 6977, Frames: 80651268, Max Reward: 9300
Iterations: 3862820, Cells: 9243, Frames: 86131224, Max Reward: 9500
Iterations: 3898876, Cells: 9294, Frames: 86925993, Max Reward: 17500
Iterations: 3970799, Cells: 9988, Frames: 88518299, Max Reward: 18500
Iterations: 3983512, Cells: 10034, Frames: 88796112, Max Reward: 19500
Iterations: 4012575, Cells: 10116, Frames: 89429866, Max Reward: 20500
Iterations: 4126501, Cells: 10648, Frames: 91943176, Max Reward: 20600
Iterations: 4129528, Cells: 10673, Frames: 92009894, Max Reward: 20900
Iterations: 4129892, Cells: 10681, Frames: 92017125, Max Reward: 21900
Iterations: 4177504, Cells: 11282, Frames: 93073347, Max Reward: 22000
Iterations: 4190708, Cells: 11352, Frames: 93360557, Max Reward: 22900
Iterations: 4348374, Cells: 12594, Frames: 96771923, Max Reward: 23000
Iterations: 4366546, Cells: 13150, Frames: 97152306, Max Reward: 23200
Iterations: 4377667, Cells: 13416, Frames: 97380833, Max Reward: 24200
Iterations: 4378041, Cells: 13421, Frames: 97388109, Max Reward: 25200
Iterations: 4406958, Cells: 13796, Frames: 97992201, Max Reward: 25500
...
Iterations: 6939517, Cells: 20224, Frames: 150848162, Max Reward: 56500
The goexplore directory now contains a more user-friendly implementation with improved logging and overall functionality. This is ideal for experimentation, but note that the current version does not include multithreading.
The goexplore directory has been moved to a separate repository