
Language Model based on The Unreasonable Effectiveness of Recurrent Neural Networks from Andrej Karapathy's blog.
General Tensorflow implementation of LSTM based Character Level Language Model to model the probability distribution of the next character in the sequence given a sequence of previous characters.
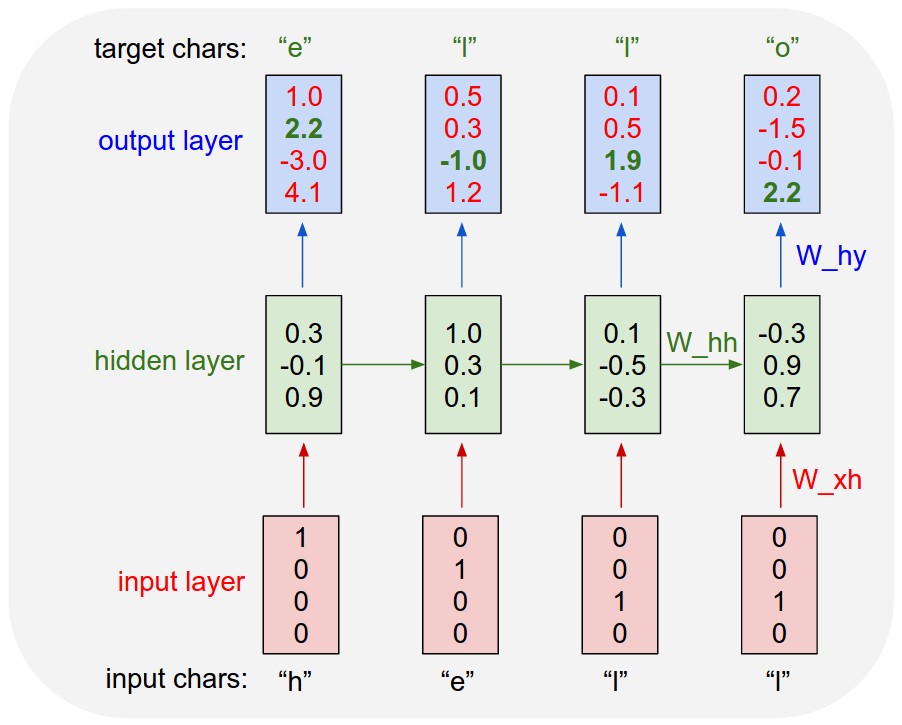
For the complete details of the dataset, preprocessing, network architecture and implementation, refer to this Wiki.
- Python 2.7
- Tensorflow
- tqdm (for displaying progress of training)
This implementation will,
-
provide support for arbitrary length input sequences by training the Recurent Network using Truncated Backpropagation Through Time (TBPTT). It reduces the problem of vanishing gradients for very long input sequences.
-
provide support for stacked LSTM layers with residual connections for efficient training of the network.
-
provide support for introducing different types of *random mutations in the input sequence for simulating real world data like,
- dropping characters in the input sequence
- introducing additional white spaces between two words
-
the input pipeline is based on Tensorflow primitive readers and queuerunners which prefetch the data making training upto 1.5-2X faster on hardware accelarators. Prefetching data reduces the total stall time of the hardware accelarators thus making their efficient use.
*Random mutations in the input sequence improve the robustness of the trained model against real world data.
-
tf.train.SequenceExamplefor storing and reading input sequence lengths of arbitrary length -
tf.contrib.training.batch_sequences_with_statesfor splitting and batching input sequences for TBPTT while maintaining the state of the recurrent network for each input example -
tf.nn.dynamic_rnnfor dynamic unrolling of each input example upto its actual length and not for the padding at the end. This is more correctness than for efficiency