We love scraping, don't we? But sometimes, we face Cloudflare protection. This script is designed to bypass the Cloudflare protection on websites, allowing you to interact with them programmatically.

If you use Selenium, you may have noticed that it is not possible to bypass Cloudflare protection with it. Even you click the "I'm not a robot" button, you will still be stuck in the "Checking your browser before accessing" page. This is because Cloudflare protection is able to detect the automation tools and block them, which puts the webdriver infinitely in the "Checking your browser before accessing" page.
As you realize, the script uses the DrissionPage, which is a controller for the browser itself. This way, the browser is not detected as a webdriver and the Cloudflare protection is bypassed.
You can install the required packages by running the following command:
pip install -r requirements.txt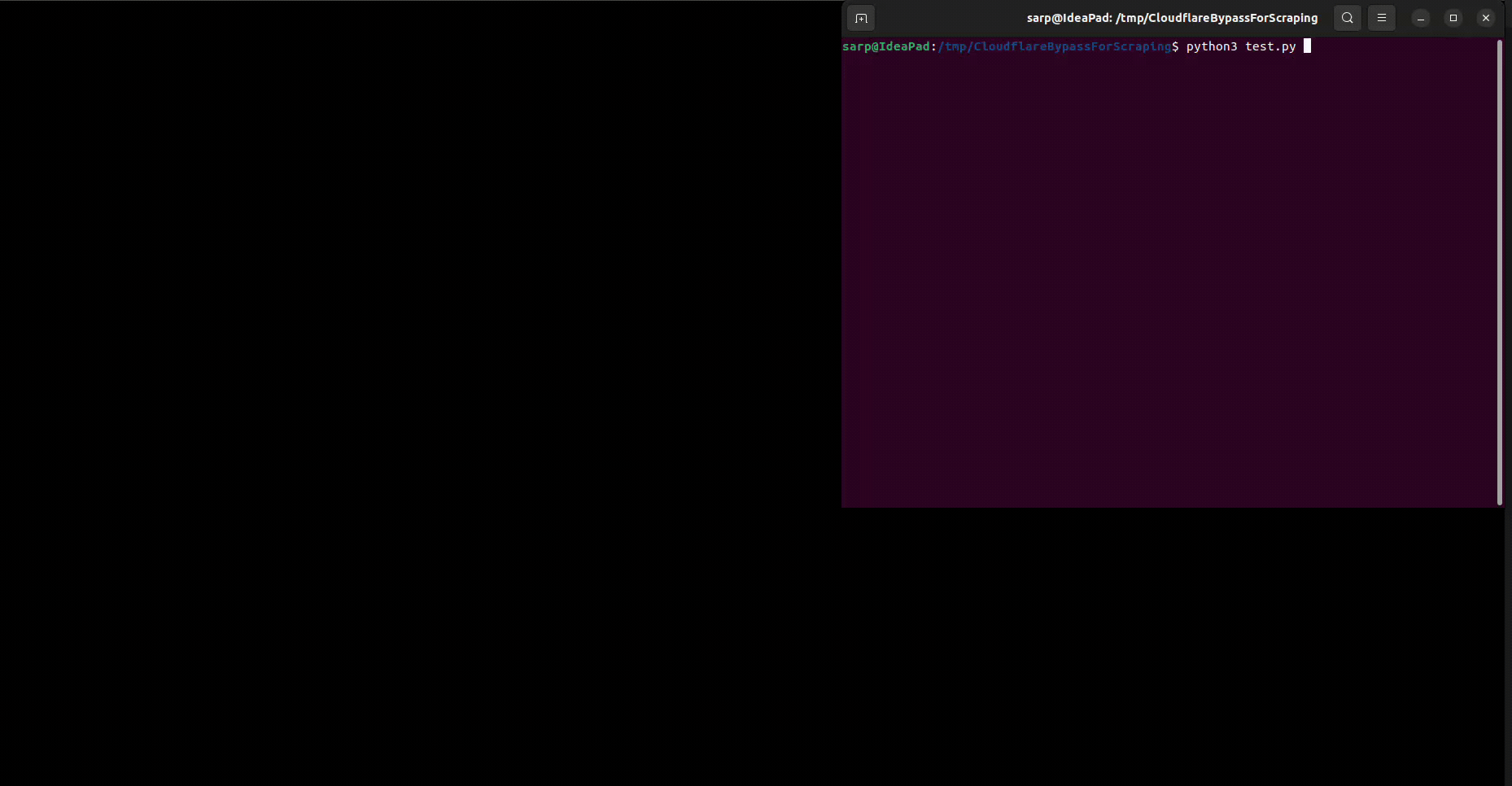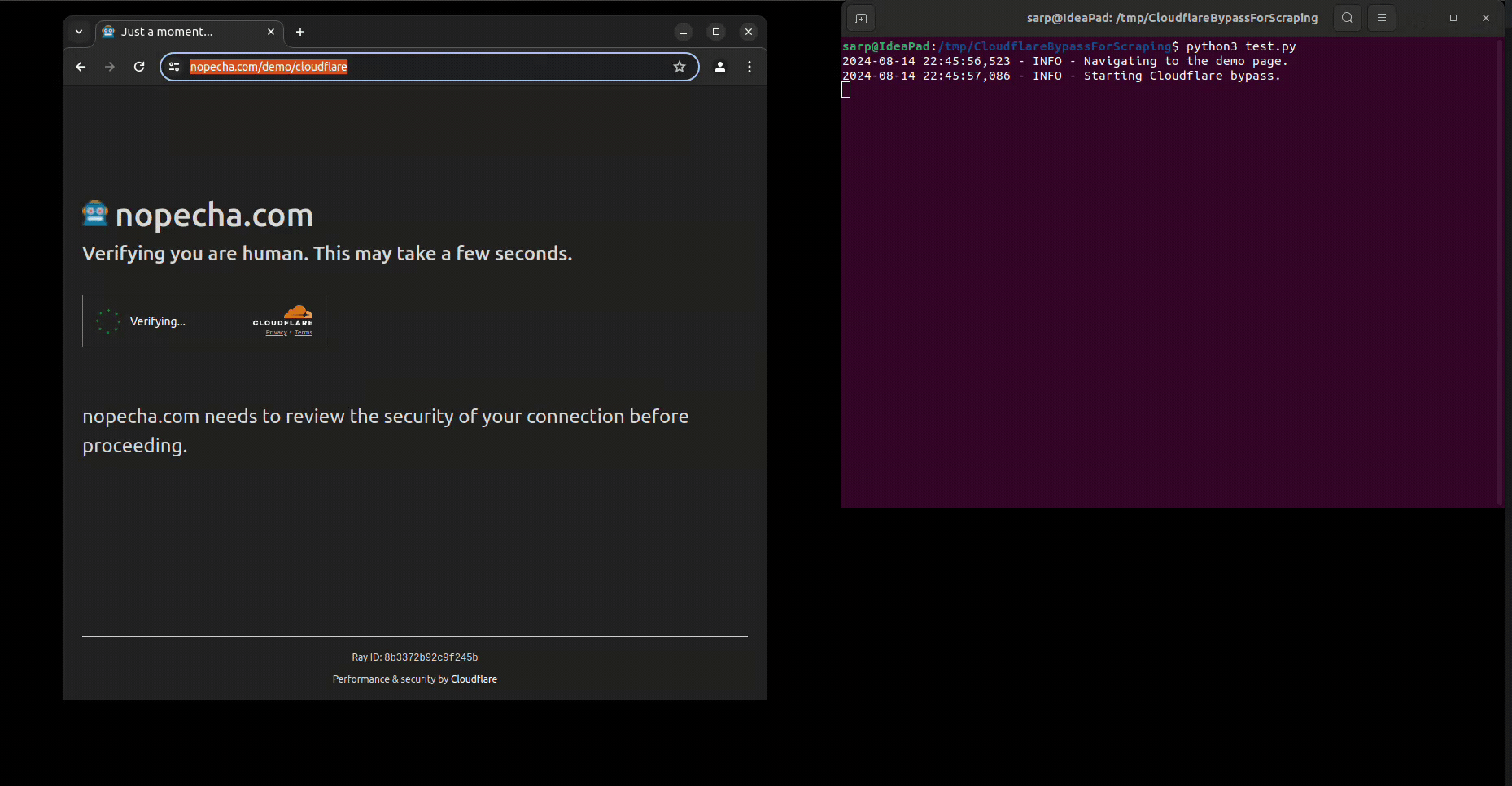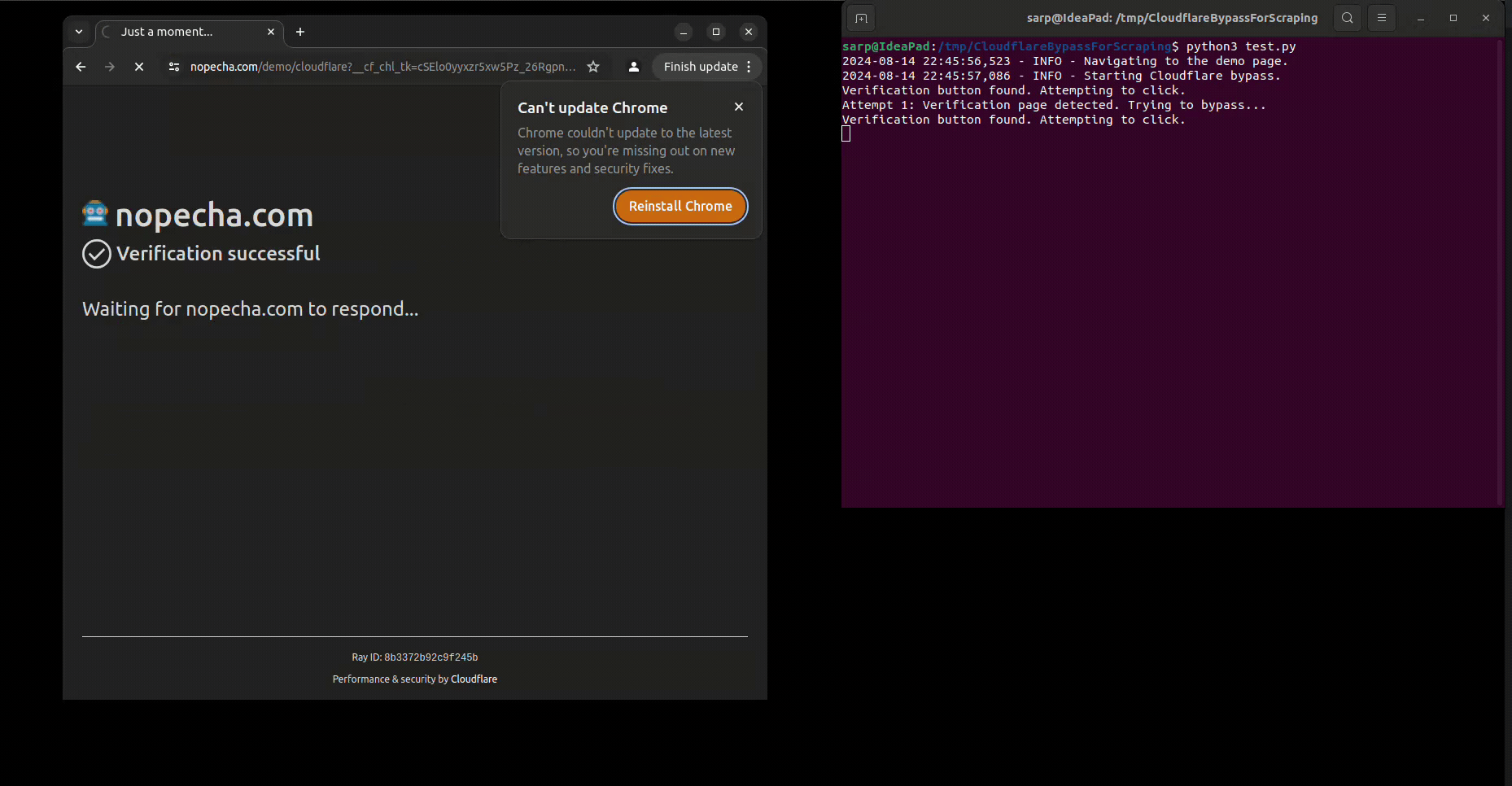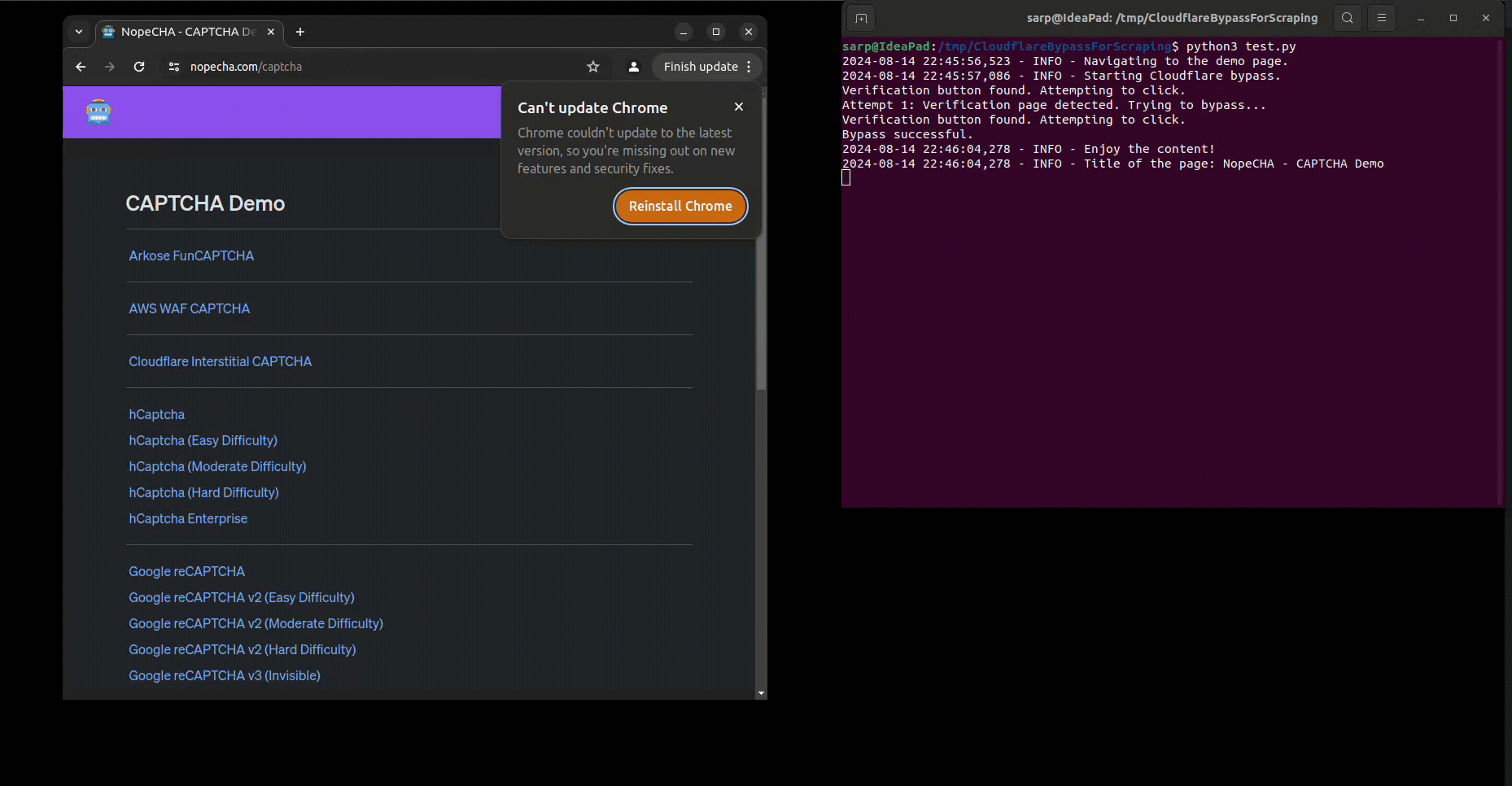
Create a new instance of the CloudflareBypass class and call the bypass method when you need to bypass the Cloudflare protection.
from CloudflareBypasser import CloudflareBypasser
from DrissionPage import ChromiumPage
driver = ChromiumPage()
driver.get('https://nopecha.com/demo/cloudflare')
cf_bypasser = CloudflareBypasser(driver)
cf_bypasser.bypass()You can run the test script to see how it works:
python test.pyRecently, @frederik-uni has introduced a new feature called "Server Mode". This feature allows you to bypass the Cloudflare protection remotely, either you can get the cookies or the HTML content of the website.
You can install the required packages by running the following command:
pip install -r server_requirements.txtStart the server by running the following command:
python server.pyTwo endpoints are available:
/cookies?url=<URL>&retries=<>: This endpoint returns the cookies of the website (including the Cloudflare cookies)./html?url=<URL>&retries=<>: This endpoint returns the HTML content of the website.
Send a GET request to the desired endpoint with the URL of the website you want to bypass the Cloudflare protection.
sarp@IdeaPad:~/$ curl http://localhost:8000/cookies?url=https://nopecha.com/demo/cloudflare
{"cookies":{"cf_clearance":"SJHuYhHrTZpXDUe8iMuzEUpJxocmOW8ougQVS0.aK5g-1723665177-1.0.1.1-5_NOoP19LQZw4TQ4BLwJmtrXBoX8JbKF5ZqsAOxRNOnW2rmDUwv4hQ7BztnsOfB9DQ06xR5hR_hsg3n8xteUCw"},"user_agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}You can also run the server in a Docker container. Thanks to @gandrunx for Dockerizing the server.
First, build the Docker image:
docker build -t cloudflare-bypass .Then, run the Docker container:
docker run -p 8000:8000 cloudflare-bypassAlternatively, you can skip docker build step, and run the container using pre-build image:
docker run -p 8000:8000 ghcr.io/sarperavci/cloudflarebypassforscraping:latestThis script is not related to bring a solution to bypass if your IP is blocked by Cloudflare. If you are blocked by Cloudflare, you need a clean IP to access the website. This script is designed to bypass the Cloudflare protection, not to bypass the IP block.
To find out more about DrissionPage, you can get more information from the following links:
Be sure you use a translation tool if you don't speak Chinese.