The mono-midi-transposition-dataset is a dataset for monophonic music with two variations to achieve free transposition representation of music. It first appears in Sequence Generation using Deep Recurrent Networks and Embeddings: A study case in music and then an updated version in A framework to compare music generative models using automatic evaluation metrics extended to rhythm
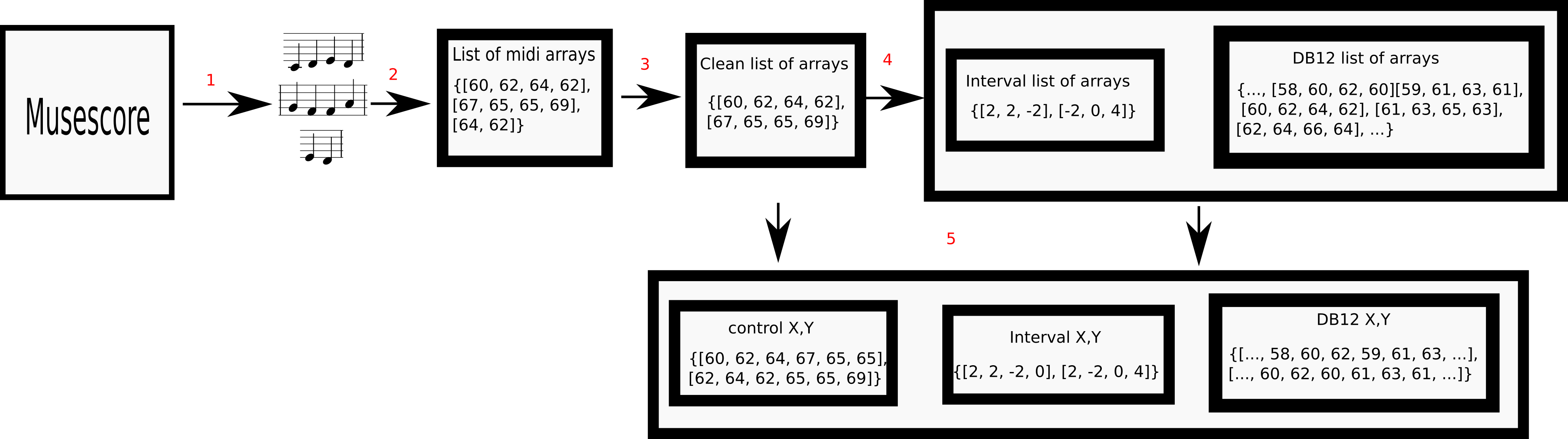
It is based in the mono-MusicXML-dataset after scraping musescore to get the midi files, cleaning the data to get rid off useless pieces and make 2 transformations to the files having 3 variations at the end.
- Control Dataset:This is the base case, on which X is the concatenated array of the original songs and Y is X shifted by one position.
- DB12 Dataset: To construct this dataset, each song is transposed 12 times (on each degree of the chromatic scale).
- Intervals Dataset: In this case, we do not have a sequence of notes, but a sequence of relative changes.
The process consists of next steps:
- Scraping: The structure of the original dataset is used as the base to download the files from the web.
- Prepossessing: Each midi is transformed into an array containing the sequence of notes
- Cleaning: only songs with more than 12 notes are kept.
- This list is used to create the interval and db12 variations
- The final list of arrays is used as the base to create 3 datasets in X,Y format
@article{garciavalencia2020sequence,
title={Sequence Generation using Deep Recurrent Networks and Embeddings: A study case in music},
author={Sebastian Garcia-Valencia and Alejandro Betancourt and Juan G. Lalinde-Pulido},
year={2020},
eprint={2012.01231},
url = {https://arxiv.org/abs/2012.01231},
journal = {ArXiv e-prints},
volume = {abs/2012.0},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
You can download the ready to use pickle files containing the data as a list of tuples []
mkdir pickles
wget -N https://www.dropbox.com/s/1qbgudr7uoet8ep/pickles.zip?dl=1 -O pickles.zip
unzip pickles.zip
rm pickles.zip
In case you want to download the midi files and apply the transformation by yourself follow next steps
Note: All is done assuming you are in your home directory
Create a root folder and clone the scripts repository for the dataset:
mkdir mono-midi-transposition-dataset
cd mono-midi-transposition-dataset
git clone https://github.com/sebasgverde/mono-midi-transposition-dataset.git
download the midi files
mkdir midi_files
wget -N https://www.dropbox.com/sh/2yruxlrvchqearr/AABO0ShVKoa_cKuSBfBwLzFGa?dl=1 -O midi_files.zip
unzip midi_files.zip -d midi_files/
unzip midi_files/train.zip -d midi_files/train/
unzip midi_files/evaluation.zip -d midi_files/evaluation/
unzip midi_files/validation.zip -d midi_files/validation/
rm midi_files.zip
rm midi_files/train.zip
rm midi_files/evaluation.zip
rm midi_files/validation.zip
set the environment and install the midi_manager package
mkvirtualenv mono_midi_dataset
pip install -r mono-midi-transposition-dataset/requirements.txt
pip install midi-manager==2.0
you can also clone the repository of midi_manager and use it as a normal package
git clone -b 2.0 --single-branch https://github.com/sebasgverde/midi-manager.git
run the main list creator script
mkdir pickles
python mono-midi-transposition-dataset/create_list_training_data.py --data_dir "midi_files/train/midi" --output_file "pickles/train_song_list.p"
python mono-midi-transposition-dataset/create_list_training_data.py --data_dir "midi_files/evaluation/midi" --output_file "pickles/evaluation_song_list.p"
python mono-midi-transposition-dataset/create_list_training_data.py --data_dir "midi_files/validation/midi" --output_file "pickles/validation_song_list.p"
run data creation script, it creates the db12 and interval variations plus clean the songs shorter than 12 notes and with durations higher than 16
python mono-midi-transposition-dataset/data_creation.py --data_dir pickles/ --base_name "train"
python mono-midi-transposition-dataset/data_creation.py --data_dir pickles/ --base_name "evaluation"
python mono-midi-transposition-dataset/data_creation.py --data_dir pickles/ --base_name "validation"
Next pseudocode summarises the procedure to create the DB12 dataset, defining a song as an ordered set of midi notes of the form {X0, X1, ..., Xsong}, where Xi is the note in the position i, with X_i in [0,127] (since these transformations are based only in pitch, time is copied at the end to each correspondent transformed element from the original tuple).
def songToDB12(self, note_sequence_vector):
centralC = 60
min_note = min(note_sequence_vector)
max_note = max(note_sequence_vector)
middle_song_point = int(math.floor((max_note - min_note)/2))
+ min_note
general_middle_gap = centralC - middle_song_point
remaining_transp = 11 - abs(general_middle_gap)
if remaining_transp >= 0:
up_transp = int(math.ceil(remaining_transp/2))
down_transp = remaining_transp - up_transp
if general_middle_gap < 0:
down_transp += abs(general_middle_gap)
else:
up_transp += abs(general_middle_gap)
else:
if general_middle_gap <= 0:
down_transp = 11
else:
up_transp = 11
tensors = [note_sequence_vector]
for i in range(down_transp):
new_note_vector = [x-(i+1) for x in note_sequence_vector]
tensors.append(new_note_vector)
for i in range(up_transp):
new_note_vector = [x+(i+1) for x in note_sequence_vector]
tensors.append(new_note_vector)
return tensors
Next pseudocode shows the strategy to convert each melody in an interval representation.
def songToInterval(self, note_sequence_vector):
tensor = []
for i in range(len(note_sequence_vector)-1):
interval = note_sequence_vector[i+1] -
note_sequence_vector[i]
tensor.append(interval)
return tensor