Here’s a download link for all of bookcorpus as of Sept 2020 #27
Comments
|
@shawwn Excellent work! It seems great, and I added the reference to it in the README in this repo! |
|
@shawwn Thanks for your efforts! However, I run into 'network error' when using the link. Anyone succeed in using the link? |
|
@shawwn This is exciting ! |
|
Sorry for the download problems. It should be fixed now. My server was running out of space due to 128GB of google cloud logs. Ideally the zip file could be mirrored elsewhere. I'd set up a torrent, but I've never done that before. If someone has a good walkthrough, feel free to link it, else I'll research it someday. |
|
@shawwn This seems excellent and I can't wait to snag a copy of the files! Unfortunately I'm running into failed downloads now as well (likely due to log proliferation again I'd presume -- incidentally, while I know nothing about setting up torrents, I'd be happy to help out with a stop-gap scripted daemon that cleans logs to keep them in check if that appeals). |
|
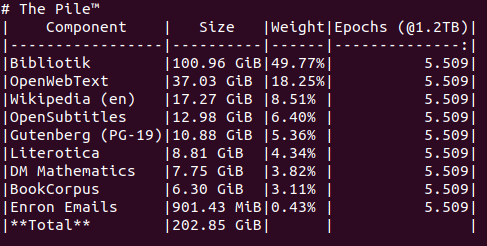
@SeanVody and everyone else: I am delighted to announce that, in cooperation with the-eye.eu, bookcorpus now has a reliable, stable download link that I expect will work for years to come: https://the-eye.eu/public/AI/pile_preliminary_components/books1.tar.gz (It's bit-for-bit identical to the file in my original tweet.) However, anyone who is looking for bookcorpus will undoubtedly be interested in everything else. I urge you to take a peek: https://the-eye.eu/public/AI/pile_preliminary_components In addition to bookcorpus (books1.tar.gz), it also has:
This is possible thanks to two organizations. First and foremost, thank you to the-eye.eu. They have a wonderful community (see discord), and they are extremely interested in archiving data for the benefit of humanity. Secondly, thank you to "The Pile", which is the project that has been meticulously gathering and preparing this training data. Join their discord if you're interested in ML: https://www.eleuther.ai/get-involved
You now have OpenAI-grade training data at your fingertips; do with it as you please. books3.tar.gz seems to be similar to OpenAI's mysterious "books2" dataset referenced in their papers. Unfortunately OpenAI will not give details, so we know very little about any differences. People suspect it's "all of libgen", but it's purely conjecture. Nonetheless, books3 is "all of bibliotik", which is possibly useful to anyone doing NLP work. I have tried to carefully and rigorously prepare the data in books3; e.g. all of the files are already preprocessed with If you have high quality datasets that you wish to make available to ML researchers, please DM me (@theshawwn) or reach out to The Pile. |

|
Great! Do we have any information about the language percentages of the database or should be considered a "main English" database? |
|
@jorditg It's mostly English, but if anyone discovers a trove of foreign .epub files, please DM me. I am quite interested in doing various foreign language versions. By the way, you can use the epub to txt converter on your own .epub files. I would be curious if it works well enough on foreign epubs, since sadly I speak only southern Texas, ya'll. |
|
+1 torrent. |
|
Happy to announce that bookcorpus was just merged into huggingface's Datasets library as |
|
Small correction @shawwn - it is And then continue to use dataset d as any other HF dataset. See the manual for more details or the dataset card for this version of bookcorpus. |
Hey, I'm experiencing failed download with link mentioned here, am I the only one? |
|
Is there a way to get the authors and titles for the books in any of those download links (in a machine readable format)? |
|
You can now download the original epub files for bookcorpus: https://battle.shawwn.com/bookcorpus-epub.tar It's 14.2GB with 17,876 epub files. The tarball also contains
@lucaguarro if you're still interested in this, you can extract that info from the epub files via the above download link. |
|
Does it include books3.tar.gz the LibGen db (in *.txt)? |
@ofou No, but I do have a copy of those epub files. Someday I'll get around to packaging them up. |
|
Thanks for answering @shawwn. The cool thing about the And it seems to keep growing!
|
Can't stop thinking about this. I think it'd be awesome to collect all this data in txt, per language, etc. Maybe I'll give it a shot! |
|
I am also interested in this corpus |
let's join forces to download it |
|
Anyone else notice that the links to the Books3 are dead ? |
|
I'm sure some threads linking to it going viral on social media factored into that ;-) There are a number of Torrents out there including The Pile v1 that have books3 in it. The whole thing is 773 GB total so you probably want to use a Torrent downloader that lets you download only some of the embeded files / directories. Edit: Evidently magnet links don't work from GH Issues, here is the whole thing: |
|
How to use the epub to txt converter at https://github.com/shawwn/scrap/blob/master/epub2txt-all on my own .epub files? |
|
Just use calibre
…On Sun, Jul 23, 2023 at 4:26 PM u7390 ***@***.***> wrote:
How to use the epub to txt converter at
https://github.com/shawwn/scrap/blob/master/epub2txt-all on my own .epub
files?
—
Reply to this email directly, view it on GitHub
<#27 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AI2QMNTYR2LXJI3HXTFSLD3XRWJJVANCNFSM4Q2GFE2A>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
|
链接貌似失效了 |
|
We recently began extracting the text layers of scholarly publications and books to include in our database. This encompasses sources such as scimag, libgen, and the latest zlib leaks. Our project, named the Standard Template Construct, also features a distributed search engine and incorporates various AI routines to handle the text corpus. Today we have releases our first dataset, STC230908. This dataset contains approximately 75,000 book texts, 1.3 million scholarly paper texts, and 24 million abstracts, including the years from 2021 to 2023. We're currently in the process of preparing the next version of the dataset, which will include an additional 300,000 books. How to Access Short Instructions:
More details: the dataset is released in IPFS and replicated to multiple nodes. It is in format of database for the search engine that we use in STC. GECK is the library that embeds this search engine and allows to stream all contained data in easy way. Even more detailed Instructions: STC GitHub Repository |
|
so weird... downloads deleted |
You can download it here: https://twitter.com/theshawwn/status/1301852133319294976?s=21
it contains 18k plain text files. The results are very high quality. I spent about a week fixing the epub2txt script, which you can find at https://github.com/shawwn/scrap named “epub2txt-all”. (not epub2txt.)
The new script:
Correctly preserves structure, matching the table of contents very closely;
Correctly renders tables of data (by default html2txt produces mostly garbage-looking results for tables),
Correctly preserves code structure, so that source code and similar things are visually coherent,
Converts numbered lists from “1\.” to “1.”
Runs the full text through ftfy.fix_text() (which is what OpenAI does for GPT), replacing Unicode apostrophes with ascii apostrophes;
Expands Unicode ellipses to “...” (three separate ascii characters).
The tarball download link (see tweet above) also includes the original ePub URLs, updated for September 2020, which ended up being about 2k more than the URLs in this repo. But they’re hard to crawl. I do have the epub files, but I’m reluctant to distribute them for obvious reasons.
The text was updated successfully, but these errors were encountered: