![]()
A collection of GPU-accelerated parallel game simulators for reinforcement learning (RL)
Note
⭐ If you find this project helpful, we would be grateful for your support through a GitHub star to help us grow the community and motivate further development!


Brax, a JAX-native physics engine, provides extremely high-speed parallel simulation for RL in continuous state space. Then, what about RL in discrete state spaces like Chess, Shogi, and Go? Pgx provides a wide variety of JAX-native game simulators! Highlighted features include:
- ⚡ Super fast in parallel execution on accelerators
- 🎲 Various game support including Backgammon, Chess, Shogi, and Go
- 🖼️ Beautiful visualization in SVG format
Read the Full Documentation for more details
Pgx is available on PyPI. Note that your Python environment has jax and jaxlib installed, depending on your hardware specification.
$ pip install pgxThe following code snippet shows a simple example of using Pgx.
You can try it out in this Colab.
Note that all step functions in Pgx environments are JAX-native., i.e., they are all JIT-able.
Please refer to the documentation for more details.
import jax
import pgx
env = pgx.make("go_19x19")
init = jax.jit(jax.vmap(env.init))
step = jax.jit(jax.vmap(env.step))
batch_size = 1024
keys = jax.random.split(jax.random.PRNGKey(42), batch_size)
state = init(keys) # vectorized states
while not (state.terminated | state.truncated).all():
action = model(state.current_player, state.observation, state.legal_action_mask)
# step(state, action, keys) for stochastic envs
state = step(state, action) # state.rewards with shape (1024, 2)Pgx is a library that focuses on faster implementations rather than just the API itself. However, the API itself is also sufficiently general. For example, all environments in Pgx can be converted to the AEC API of PettingZoo, and you can run Pgx environments through the PettingZoo API. You can see the demonstration in this Colab.
📣 API v2 (v2.0.0)
Pgx has been updated from API v1 to v2 as of November 8, 2023 (release v2.0.0). As a result, the signature for Env.step has changed as follows:
- v1:
step(state: State, action: Array) - v2:
step(state: State, action: Array, key: Optional[PRNGKey] = None)
Also, pgx.experimental.auto_reset are changed to specify key as the third argument.
Purpose of the update: In API v1, even in environments with stochastic state transitions, the state transitions were deterministic, determined by the _rng_key inside the state. This was intentional, with the aim of increasing reproducibility. However, when using planning algorithms in this environment, there is a risk that information about the underlying true randomness could "leak." To make it easier for users to conduct correct experiments, Env.step has been changed to explicitly specify a key.
Impact of the update: Since the key is optional, it is still possible to execute as env.step(state, action) like API v1 in deterministic environments like Go and chess, so there is no impact on these games. As of v2.0.0, only 2048, backgammon, and MinAtar suite are affected by this change.
| Backgammon | Chess | Shogi | Go |
|---|---|---|---|
  |
  |
  |
  |
Use pgx.available_envs() -> Tuple[EnvId] to see the list of currently available games. Given an <EnvId>, you can create the environment via
>>> env = pgx.make(<EnvId>)| Game/EnvId | Visualization | Version | Five-word description by ChatGPT |
|---|---|---|---|
2048 "2048" |
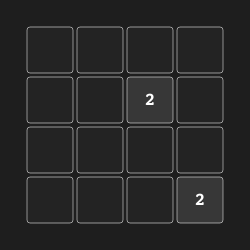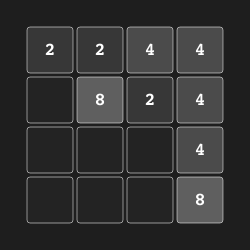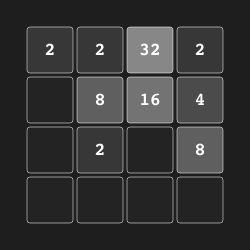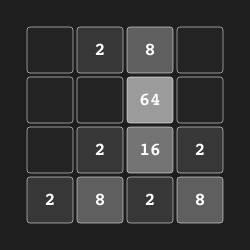 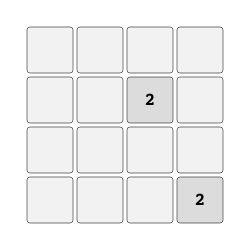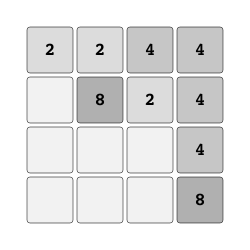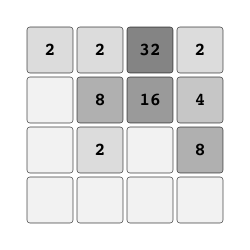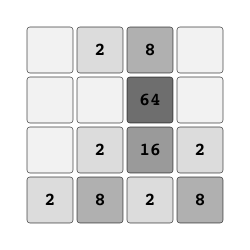 |
v2 |
Merge tiles to create 2048. |
Animal Shogi"animal_shogi" |
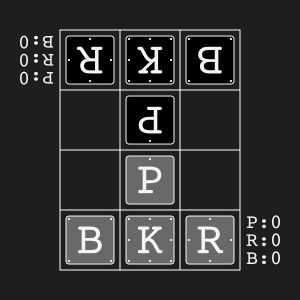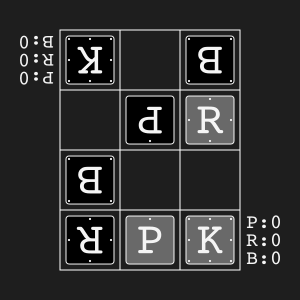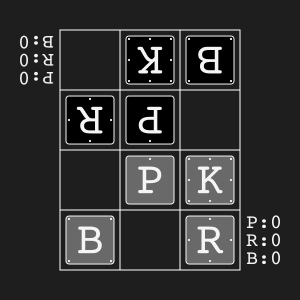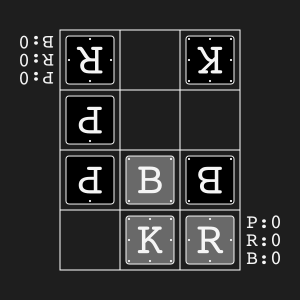 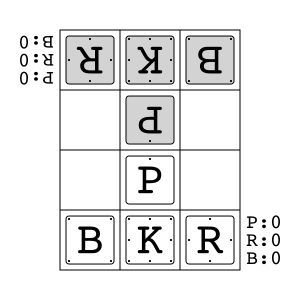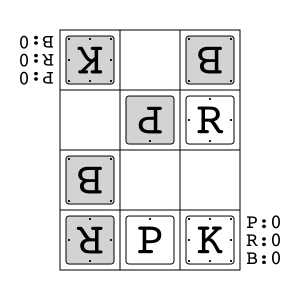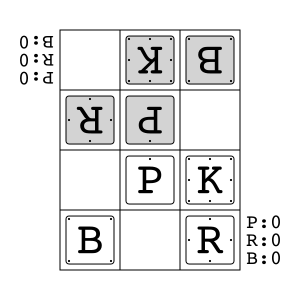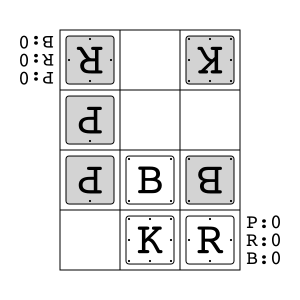 |
v2 |
Animal-themed child-friendly shogi. |
Backgammon"backgammon" |
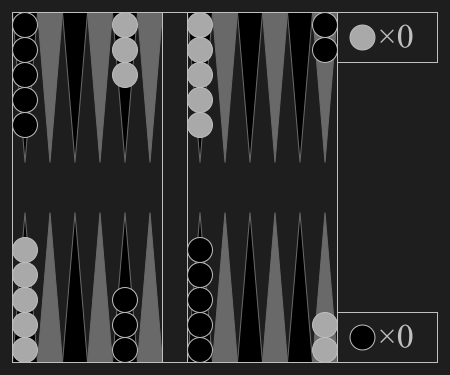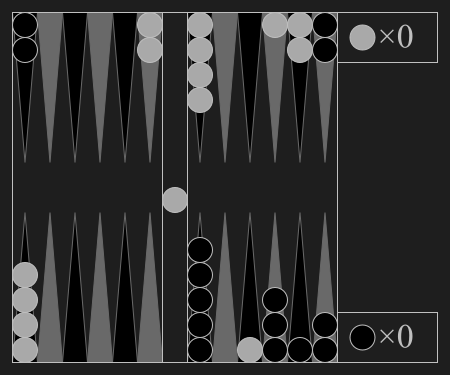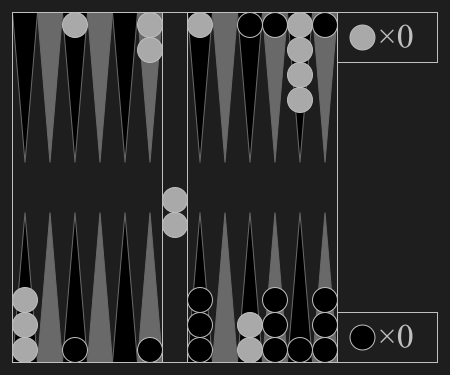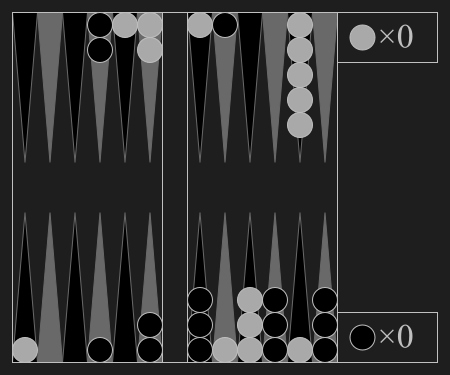 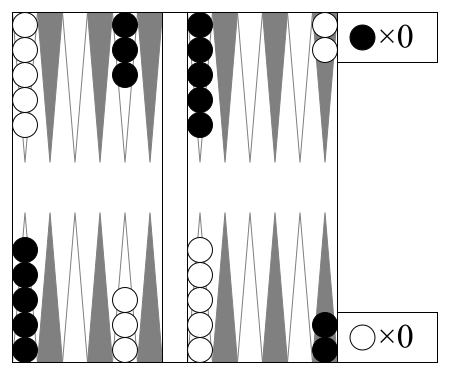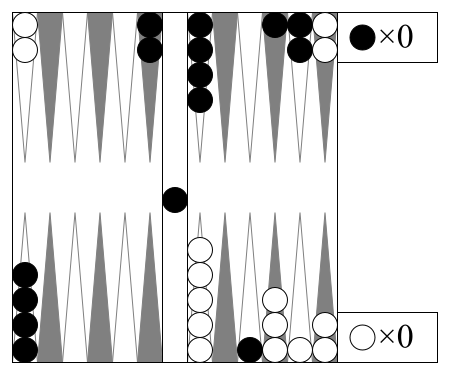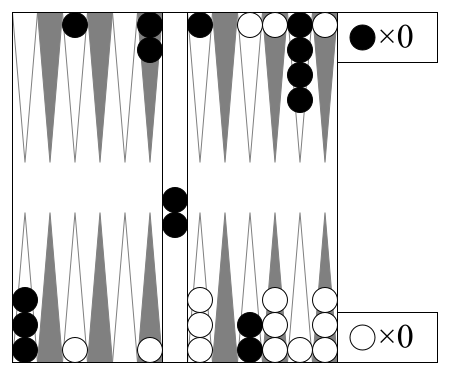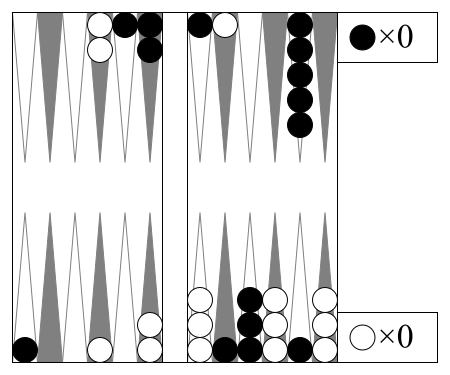 |
v2 |
Luck aids bearing off checkers. |
Bridge bidding"bridge_bidding" |
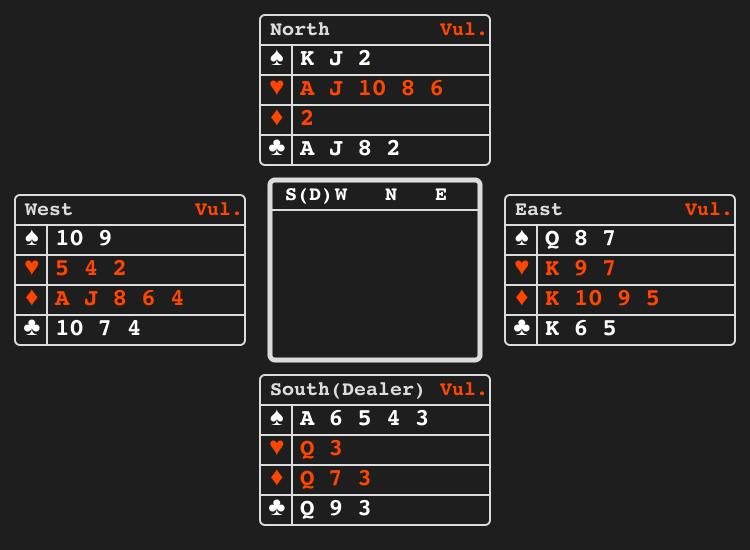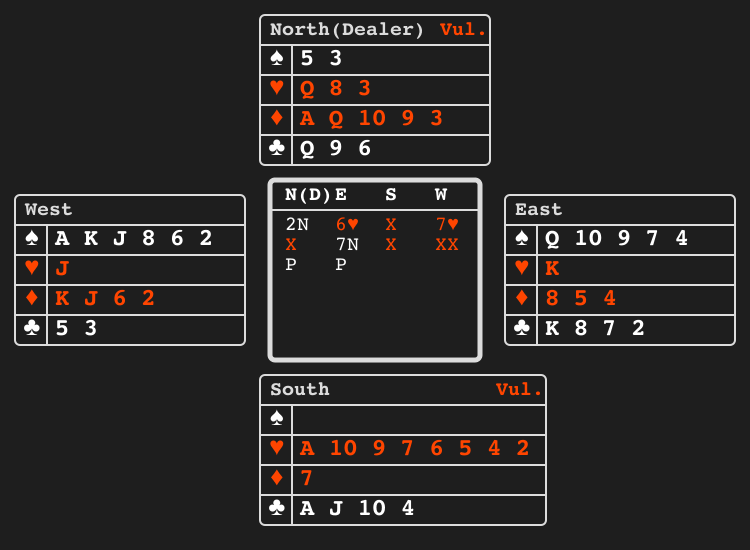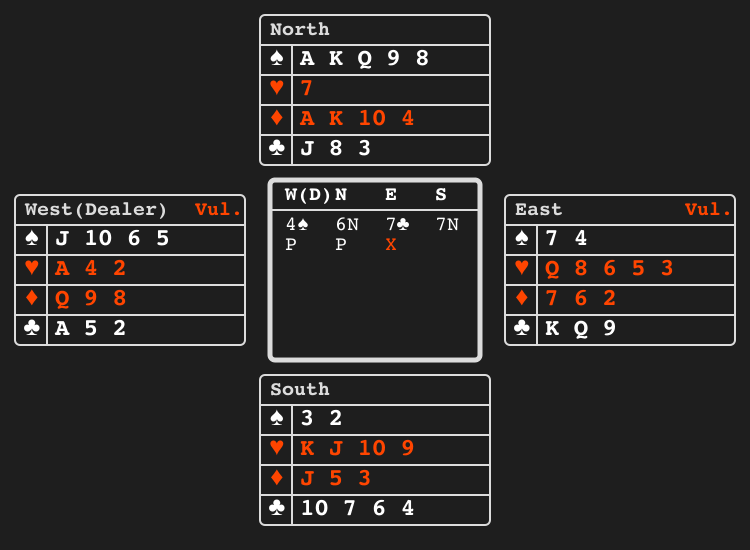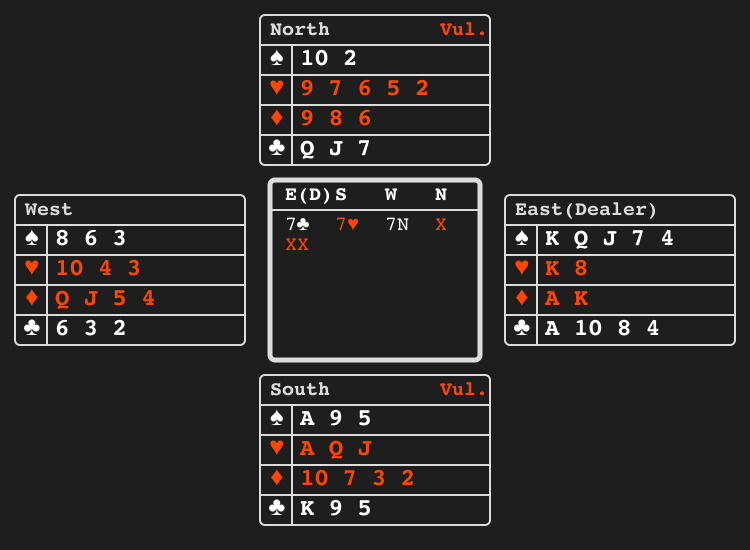 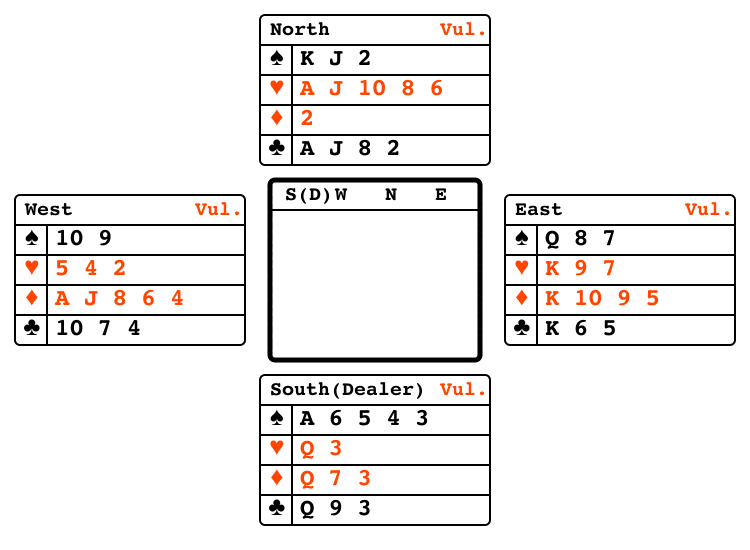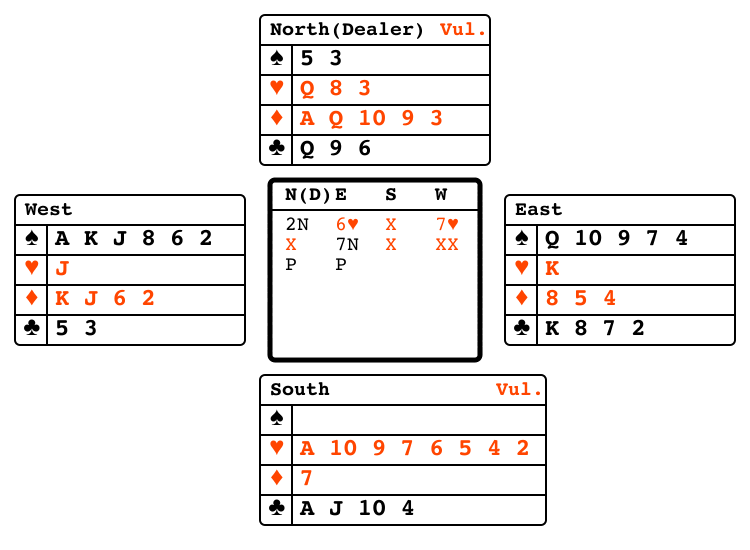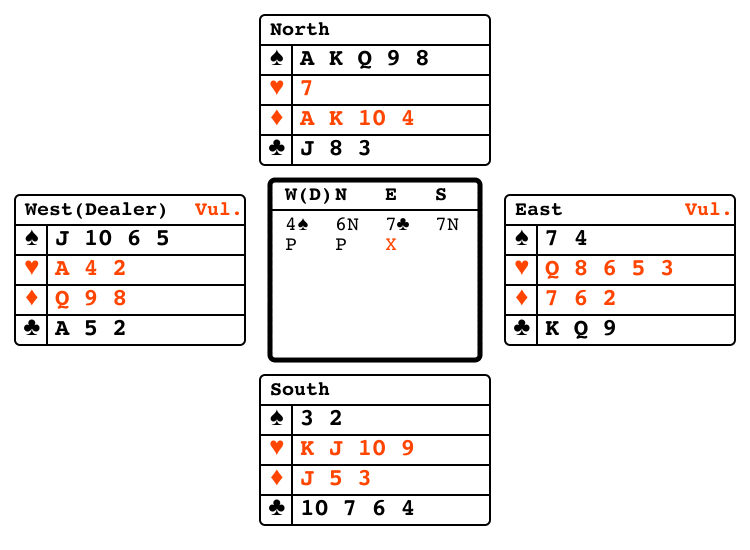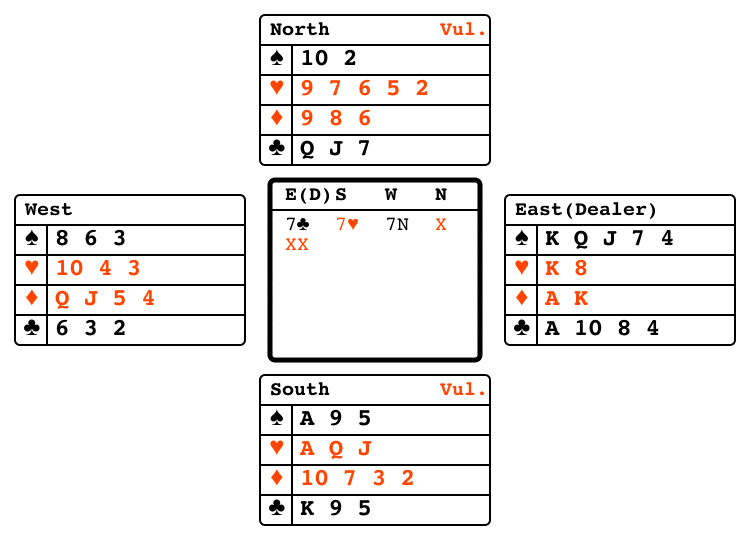 |
v1 |
Partners exchange information via bids. |
Chess"chess" |
  |
v2 |
Checkmate opponent's king to win. |
Connect Four"connect_four" |
  |
v0 |
Connect discs, win with four. |
Gardner Chess"gardner_chess" |
  |
v0 |
5x5 chess variant, excluding castling. |
Go"go_9x9" "go_19x19" |
 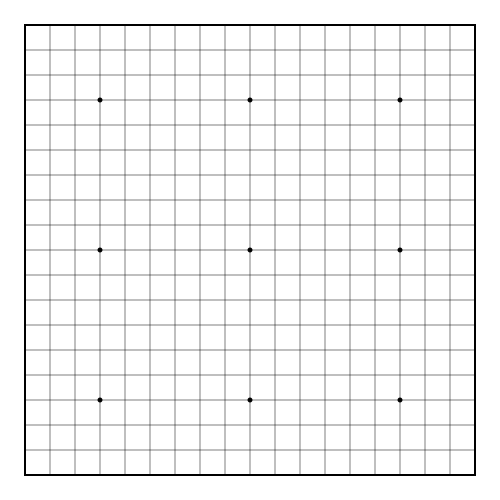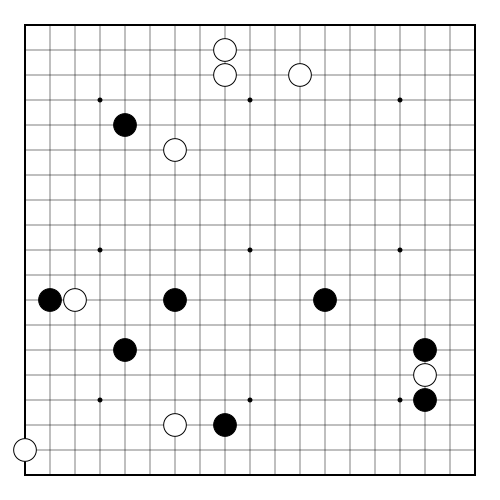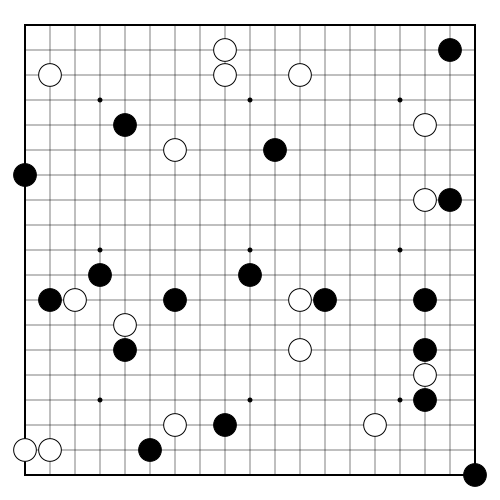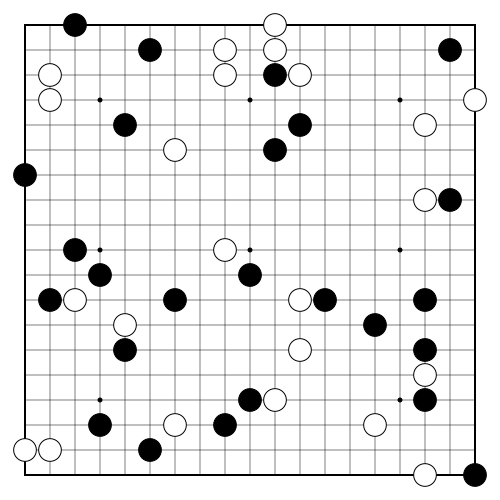 |
v1 |
Strategically place stones, claim territory. |
Hex"hex" |
  |
v0 |
Connect opposite sides, block opponent. |
Kuhn Poker"kuhn_poker" |
  |
v1 |
Three-card betting and bluffing game. |
Leduc hold'em"leduc_holdem" |
 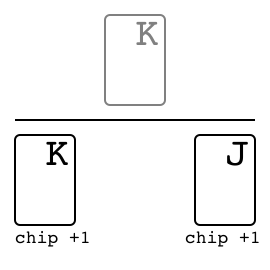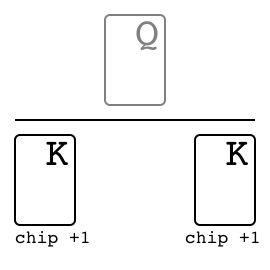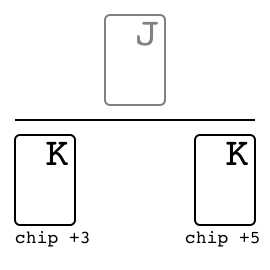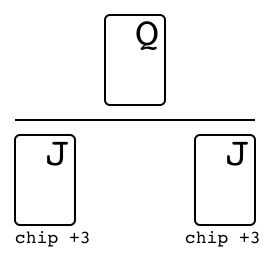 |
v0 |
Two-suit, limited deck poker. |
MinAtar/Asterix"minatar-asterix" |
 |
v1 |
Avoid enemies, collect treasure, survive. |
MinAtar/Breakout"minatar-breakout" |
 |
v1 |
Paddle, ball, bricks, bounce, clear. |
MinAtar/Freeway"minatar-freeway" |
 |
v1 |
Dodging cars, climbing up freeway. |
MinAtar/Seaquest"minatar-seaquest" |
 |
v1 |
Underwater submarine rescue and combat. |
MinAtar/SpaceInvaders"minatar-space_invaders" |
 |
v1 |
Alien shooter game, dodge bullets. |
Othello"othello" |
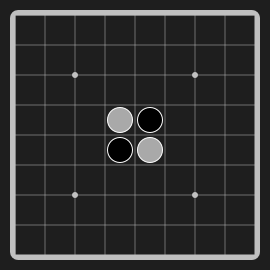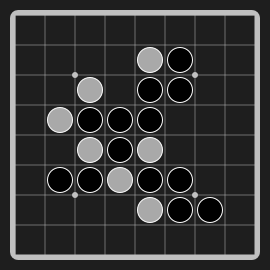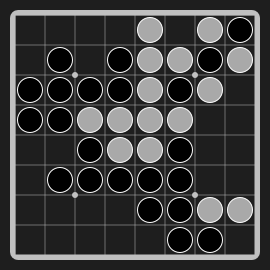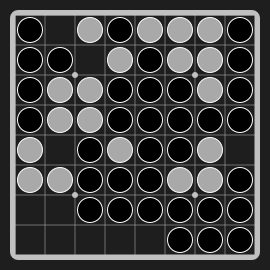 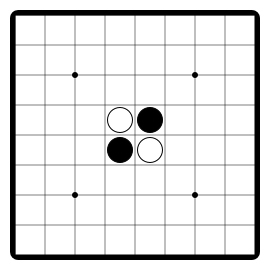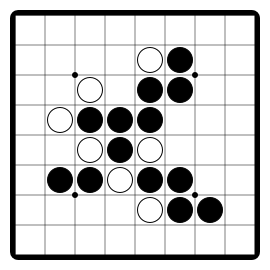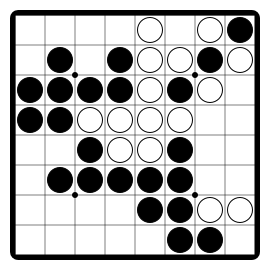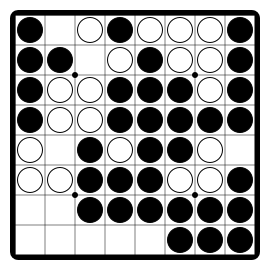 |
v0 |
Flip and conquer opponent's pieces. |
Shogi"shogi" |
 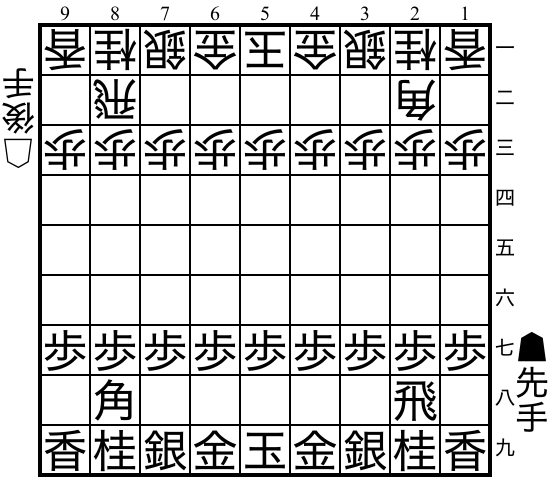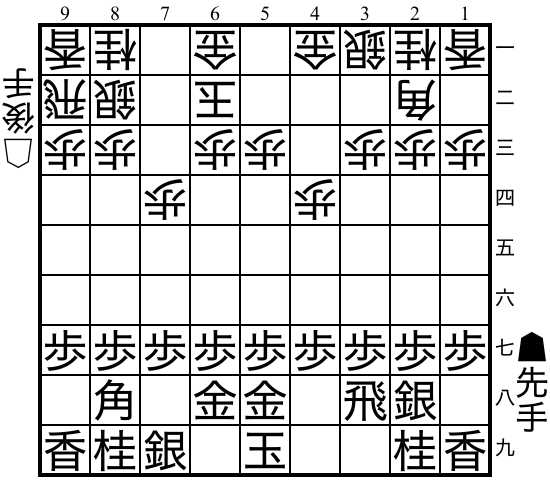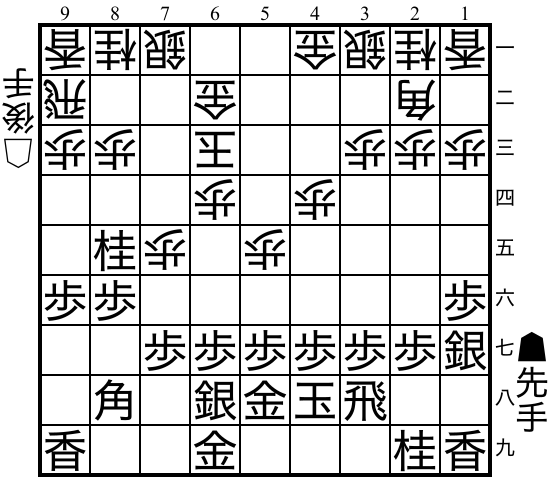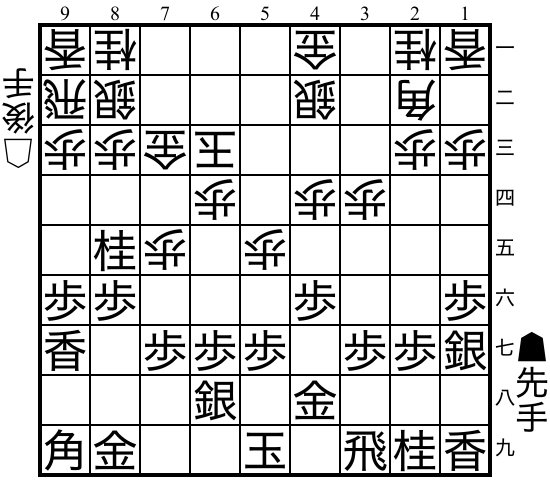 |
v0 |
Japanese chess with captured pieces. |
Sparrow Mahjong"sparrow_mahjong" |
  |
v1 |
A simplified, children-friendly Mahjong. |
Tic-tac-toe"tic_tac_toe" |
  |
v0 |
Three in a row wins. |
Versioning policy
Each environment is versioned, and the version is incremented when there are changes that affect the performance of agents or when there are changes that are not backward compatible with the API. If you want to pursue complete reproducibility, we recommend that you check the version of Pgx and each environment as follows:
>>> pgx.__version__
'1.0.0'
>>> env.version
'v0'Pgx is intended to complement these JAX-native environments with (classic) board game suits:
- RobertTLange/gymnax: JAX implementation of popular RL environments (classic control, bsuite, MinAtar, etc) and meta RL tasks
- google/brax: Rigidbody physics simulation in JAX and continuous-space RL tasks (ant, fetch, humanoid, etc)
- instadeepai/jumanji: A suite of diverse and challenging RL environments in JAX (bin-packing, routing problems, etc)
- flairox/jaxmarl: Multi-Agent RL environments in JAX (simplified StarCraft, etc)
- corl-team/xland-minigrid: Meta-RL gridworld environments in JAX inspired by MiniGrid and XLand
- MichaelTMatthews/Craftax: (Crafter + NetHack) in JAX for open-ended RL
- epignatelli/navix: Re-implementation of MiniGrid in JAX
Combining Pgx with these JAX-native algorithms/implementations might be an interesting direction:
- Anakin framework: Highly efficient RL framework that works with JAX-native environments on TPUs
- deepmind/mctx: JAX-native MCTS implementations, including AlphaZero and MuZero
- deepmind/rlax: JAX-native RL components
- google/evojax: Hardware-Accelerated neuroevolution
- RobertTLange/evosax: JAX-native evolution strategy (ES) implementations
- adaptive-intelligent-robotics/QDax: JAX-native Quality-Diversity (QD) algorithms
- luchris429/purejaxrl: Jax-native RL implementations
Currently, some environments, including Go and chess, do not perform well on TPUs. Please use GPUs instead.
If you use Pgx in your work, please cite our paper:
@inproceedings{koyamada2023pgx,
title={Pgx: Hardware-Accelerated Parallel Game Simulators for Reinforcement Learning},
author={Koyamada, Sotetsu and Okano, Shinri and Nishimori, Soichiro and Murata, Yu and Habara, Keigo and Kita, Haruka and Ishii, Shin},
booktitle={Advances in Neural Information Processing Systems},
pages={45716--45743},
volume={36},
year={2023}
}
Apache-2.0