Critical Notice: GGUF was introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. The main branch will keep using the deprecated variant. Switch to the gguf-fix branch for GGUF support.

docker pull su77ungr/casalioy:stabledocker run -it -p 8501:8501 --shm-size=16gb su77ungr/casalioy:stable /bin/bashfor GPU support of stable use casalioy:gpu (unstable)
All set! Proceed with ingesting your dataset
First install all requirements:
python -m pip install poetry
python -m poetry config virtualenvs.in-project true
python -m poetry install
. .venv/bin/activate
python -m pip install --force streamlit sentence_transformers # Temporary bandaid fix, waiting for streamlit >=1.23
pre-commit installIf you want GPU support for llama-ccp:
pip uninstall -y llama-cpp-python
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install --force llama-cpp-pythonEdit the example.env to fit your models and rename it to .env
# Generic
MODEL_N_CTX=1024
TEXT_EMBEDDINGS_MODEL=sentence-transformers/all-MiniLM-L6-v2
TEXT_EMBEDDINGS_MODEL_TYPE=HF # LlamaCpp or HF
USE_MLOCK=true
# Ingestion
PERSIST_DIRECTORY=db
DOCUMENTS_DIRECTORY=source_documents
INGEST_CHUNK_SIZE=500
INGEST_CHUNK_OVERLAP=50
# Generation
MODEL_TYPE=LlamaCpp # GPT4All or LlamaCpp
MODEL_PATH=TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF/tinyllama-1.1b-chat-v0.3.Q6_K.gguf
MODEL_TEMP=0.8
MODEL_STOP=[STOP]
CHAIN_TYPE=stuff
N_RETRIEVE_DOCUMENTS=100 # How many documents to retrieve from the db
N_FORWARD_DOCUMENTS=6 # How many documents to forward to the LLM, chosen among those retrievedThis should look like this
└── repo
├── startLLM.py
├── casalioy
│ └── ingest.py, load_env.py, startLLM.py, gui.py, ...
│ └── misc/
├── source_documents
│ └── sample.csv
│ └── ...
├── models
│ ├── ggml-vic7b-q5_1.bin
│ └── ...
└── .env, Dockerfile, ...
👇 Update your installation!
git pull && poetry install
To automatically ingest different data types (.txt, .pdf, .csv, .epub, .html, .docx, .pptx, .eml, .msg)
This repo includes dummy files inside
source_documentsto run tests with.
python casalioy/ingest.py # optional <path_to_your_data_directory>Optional: use y flag to purge existing vectorstore and initialize fresh instance
python casalioy/ingest.py # optional <path_to_your_data_directory> yThis spins up a local qdrant namespace inside the db folder containing the local vectorstore. Will take time,
depending on the size of your document.
You can ingest as many documents as you want by running ingest, and all will be accumulated in the local embeddings
database. To remove dataset simply remove db folder.
In order to ask a question, run a command like:
python casalioy/startLLM.pyAnd wait for the script to require your input.
> Enter a query:Hit enter. You'll need to wait 20-30 seconds (depending on your machine) while the LLM model consumes the prompt and prepares the answer. Once done, it will print the answer and the 4 sources it used as context from your documents; you can then ask another question without re-running the script, just wait for the prompt again.
Note: you could turn off your internet connection, and the script inference would still work. No data gets out of your local environment.
Type exit to finish the script.
Introduced by @alxspiker -> see #21
streamlit run casalioy/gui.pyList of available open LLMs HuggingFace
🪢 avoid using non-v3 models when using other quantization than q5 (LlamaCpp introduced v3 for ggml)
| Model | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | Avg. |
|---|---|---|---|---|---|---|---|---|
| GPT4All-13b-snoozy GGMLv3 | ||||||||
| GPT4All-13b-snoozy (deprecated) | 83.3 | 79.2 | 75.0 | 71.3 | 60.9 | 44.2 | 43.4 | 65.3 |
| Model | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | Avg. |
|---|---|---|---|---|---|---|---|---|
| GPT4All-J vanilla | 73.4 | 74.8 | 63.4 | 64.7 | 54.9 | 36.0 | 40.2 | 58.2 |
| GPT4All-J v1.1-breezy | 74.0 | 75.1 | 63.2 | 63.6 | 55.4 | 34.9 | 38.4 | 57.8 |
| GPT4All-J v1.2-jazzy | 74.8 | 74.9 | 63.6 | 63.8 | 56.6 | 35.3 | 41.0 | 58.6 |
| GPT4All-J v1.3-groovy | 73.6 | 74.3 | 63.8 | 63.5 | 57.7 | 35.0 | 38.8 | 58.1 |
| GPT4All-J Lora 6B | 68.6 | 75.8 | 66.2 | 63.5 | 56.4 | 35.7 | 40.2 | 58.1 |
all the supported models from here (custom LLMs in Pipeline)
- Download ready-to-use models
Browse Hugging Face for models
- Convert locally
python casalioy/misc/convert.pysee discussion
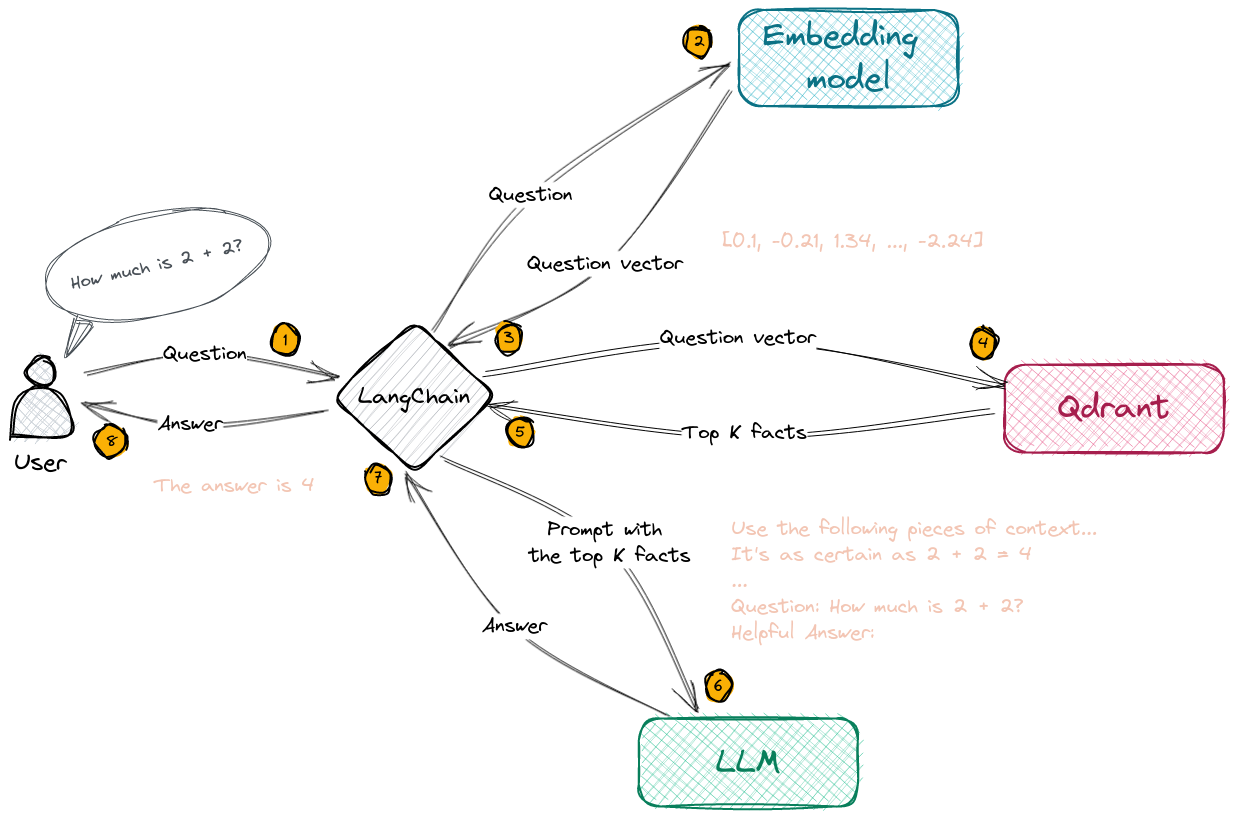
Selecting the right local models and the power of LangChain you can run the entire pipeline locally, without any data
leaving your environment, and with reasonable performance.
-
ingest.pyusesLangChaintools to parse the document and create embeddings locally usingLlamaCppEmbeddings. It then stores the result in a local vector database usingQdrantvector store. -
startLLM.pycan handle every LLM that is llamacpp compatible (defaultGPT4All-J). The context for the answers is extracted from the local vector store using a similarity search to locate the right piece of context from the docs.
The contents of this repository are provided "as is" and without warranties of any kind, whether express or implied. We do not warrant or represent that the information contained in this repository is accurate, complete, or up-to-date. We expressly disclaim any and all liability for any errors or omissions in the content of this repository.
By using this repository, you are agreeing to comply with and be bound by the above disclaimer. If you do not agree with any part of this disclaimer, please do not use this repository.