Update 2021-6: We now provide a new hold-out testset of AiR-D for benchmarking task-driven saliency prediction and scanpath prediction!
This code implements the Attention with Reasoning capability (AiR) framework. It contains three principal components:
- AiR-E: an quantitative evaluation method for measuring the alignments between different attentions and reasoning process,
- AiR-M: an attention supervision method for learning attention progressively throughout the reasoning process, and
- AiR-D: the first human eye-tracking dataset for Visual Question Answering task.
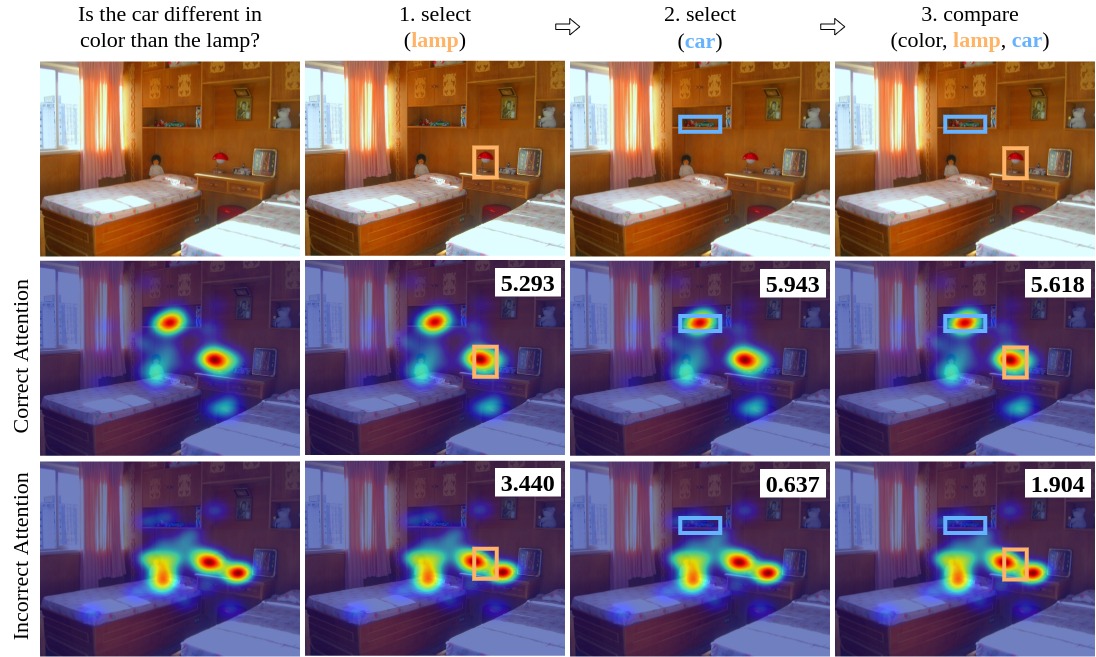
An example for evaluating the human attentions with correct and incorrect answers is illustrated below.
If you use our code or data, please cite our paper:
@InProceedings{air,
author = {Chen, Shi and Jiang, Ming and Yang, Jinhui and Zhao, Qi},
title = {AiR: Attention with Reasoning Capability},
booktitle = {ECCV},
year = {2020}
}
We adopt the official implementation of the Bilinear Attention Network as a backbone model for attention supervision. We use the bottom-up features provided in this repository. For GRU with Bayesian Dropout (used in our UpDown reimplementation), we adopt the implementation from this repository. Please refer to these links for further README information.
- Requirements for Pytorch. We use Pytorch 1.2.0 in our experiments.
- Requirements for Tensorflow. We only use the tensorboard for visualization.
- Python 3.6+ (for most of our experiments)
- Python 2.7 (only for extracting features from the tsv files)
- You may need to install the OpenCV package (CV2) for Python.
- Download the GQA Dataset.
- Download the bottom-up features and unzip it.
- Extracting features from the raw tsv files (Important: You need to run the code with Python 2):
python2 ./pre_processing/extract_tsv.py --input $TSV_FILE --output $FEATURE_DIR
- Generate our atomic operations abstracted from GQA annotations:
python ./pre_processing/process_semantics.py --question $GQA_ROOT/question --scene_graph $GQA_ROOT/scene_graph --mapping ./data --save ./data
- Generate ground truth attention mask for supervision:
python ./pre_processing/generate_att_mask.py --bbox_dir $FEATURE_DIR/box --question $GQA_ROOT/question --scene_graph $GQA_ROOT/scene_graph --semantics ./data --save ./AiR-M/processed_data
The AiR-E score can be computed with:
python ./AiR-E/attention_eval.py --image $GQA_ROOT/images --question $GQA_ROOT/question --scene_graph $GQA_ROOT/scene_graph --semantics ./data --att_dir $ATTENTION_DIR --bbox_dir $FEATURE_DIR/box --att_type ATTENTION_TYPE --save ./data
For evaluating the human attention in our dataset, specify ATTENTION_TYPE as human and $ATTENTION_DIR as the directory storing the saliency maps. For evaluating machine attention, specify ATTENTION_TYPE as spatial or object and $ATTENTION_DIR as the file storing the attention. Our code assumes the machine attention is stored in a Numpy dictionary where the keys are qid and values are the maps. We use spatial attention with spatial size 7x7 and object-based attention with size 36.
The output is a Json file storing the scores. You can access the scores for a specific question (for example qid 011000868) as:
>>> import json
>>> data = json.load(open('./data/att_score.json'))
>>> data['011000868']
[['select', 1, '7.908'], ['relate', 2, '7.053'], ['query', 3, '6.197']]
For each step, the result contains the reasoning operation, level of dependency in the process, and the AiR-E score.
We provide the implementation of our method on two state-of-the-art VQA models, including UpDown and BAN. Before training with our method, you need to first generate the dictionary for questions and answers:
cd ./AiR-E
python preprocess_lang.py --question $GQA_ROOT/question
Then the training process for UpDown can be called as:
python main_updown.py --mode train --anno_dir $GQA_ROOT/question --prep_dir ./processed_data --img_dir $FEATURE_DIR/features --checkpoint_dir $CHECKPOINT --ss_factor 2 --ss_step 1
We implement a schedule sampling strategy for optimizing the operation prediction. However, it did not contribute too much in boosting the performance and thus we disabled it in our experiments with --ss_factor 2 and --ss_step 1. If you want to enable it, simply replace the increase factor and step with appropriate values (e.g., --ss_factor 0.2 and --ss_step 3).
For training with BAN, you need to input the bounding box positions as well:
python main_ban.py --mode train --anno_dir $GQA_ROOT/question --prep_dir ./processed_data --img_dir $FEATURE_DIR/features --bbox_dir $FEATURE_DIR/box --checkpoint_dir $CHECKPOINT --ss_factor 2 --ss_step 1
Evaluating the performance on the GQA test-dev set:
python main_updown.py --mode eval --anno_dir $GQA_ROOT/question --prep_dir ./processed_data --img_dir $FEATURE_DIR/features --weights $CHECKPOINT/model_best.pth
Note that it will also generate the predicted attentions, answers and operations. To generate the data on validation set (for comparison with human attention in our AiR-D dataset), simply modify line 27 of ./AiR-M/util/dataloader.py to load the annotations of validation set.
To create a submission for the GQA online server (test-standard set), call:
python main_updown.py --mode submission --anno_dir $GQA_ROOT/question --prep_dir ./processed_data --img_dir $FEATURE_DIR/features --weights $CHECKPOINT/model_best.pth
Our data is available at https://drive.google.com/file/d/1_yWlv3GXYw0-qBan5pPEmV8vd-Y8Duh5/view?usp=sharing. We provide both the saliency maps with aggregated fixations throughout the reasoning process (aggregated_maps) and the saliency maps for different time steps (temporal_maps). Saliency maps for correct and incorrect answers are stored in different folders (fixmaps_corr and fixmaps_incorr), and the saliency maps regardless of answer correctness are stored in fixmaps. For the saliency maps of different time steps, we highlight their starting times (e.g., _1s for saliency maps of 1-2 second), and put them in different folders.
We also provide the raw fixation sequences (scanpath) for AiR-D, available at https://drive.google.com/file/d/1HFlX09kRB2lOa6qYihFjQ0Q8KSvxfPcZ/view?usp=sharing. The data contains both the answer responses from our participants and their fixation sequences. The responses are stored in consolidated_answers.json (nan means the participant does not attempt the question), together with the ground truth answers. The fixations sequences are stored in the fix folder, where each mat file corresponds to the sequence of a single participant (anonymized) on the specific question. The location and time interval (starting time and end time) of a fixation are stored under the name xy and t, respectively.
A new computational model is developed for task-driven scanpath prediction, please refer to this repo for details.
We now provide a new hold-out testset for evaluating task-driven attention modeling. The testset consists two evaluation splits, including general split that is agnostic to answer correctness, and the correctness split for evaluation with both correct and incorrect attention. For each sample in the testset, we provide its GQA IDs (question ID and image ID), the corresponding split in the GQA dataset, and the question-answer pair. The eye-tracking annotations are kept private, and only for evaluation purpose.
To evaluate your models with the testset, please email your results to chen4595@umn.edu. The results should be in the following formats:
For saliency prediction, we accept results in the form of saliency maps stored as PNG files. Each result should be named based on the corresponding question ID in the GQA dataset. Results for different splits should be organized as:
<AiR-saliency>
-- ./general_split # results for the general split
201064885.png # saliency map for sample with qid 201064885
201735202.png
...
-- ./correctness_split # results for the correctness split
-- ./correctness_split/correct # saliency maps for correct attention
19209372.png
16934027.png
...
-- ./correctness_split/incorrect # saliency maps for incorrect attention
19209372.png
16934027.png
...
For scanpath prediction, we accept result in the form of JSON files. Please submit a single file for the general split (i.e., air_scanpath_general.json), and two separate files for the correctness split (i.e., air_scanpath_correct.json and air_scanpath_incorrect.json). Our evaluation is carried out on 10 generated scanpaths for each sample, and assumes scanpaths for images with width and height equals 320 and 240. Each scanpath should include the information for a sequence of fixations, including their x-axis, y-axis and duration. An example for the submission file is include here, where the question IDs are used as keys.