Writing code in a programming language for a designed graphical user interface created by, is done mostly by developers to build and develop custom websites and software. The development work is not approachable by those unfamiliar with programming, to drive these personas capable of developing the code bases we come up with an automated system. Here we proposed that methods of deep learning and computer vision techniques can be grasped to train a model that will automatically generate HTML codes from a single input mockup image and try to build an end-to-end automated system with a good amount of accuracy over the dataset the model is trained, for developing web pages.
The research work and project is done in my undergrad thesis, you can find it here on my site.
Live Demo: Hugging Face Space
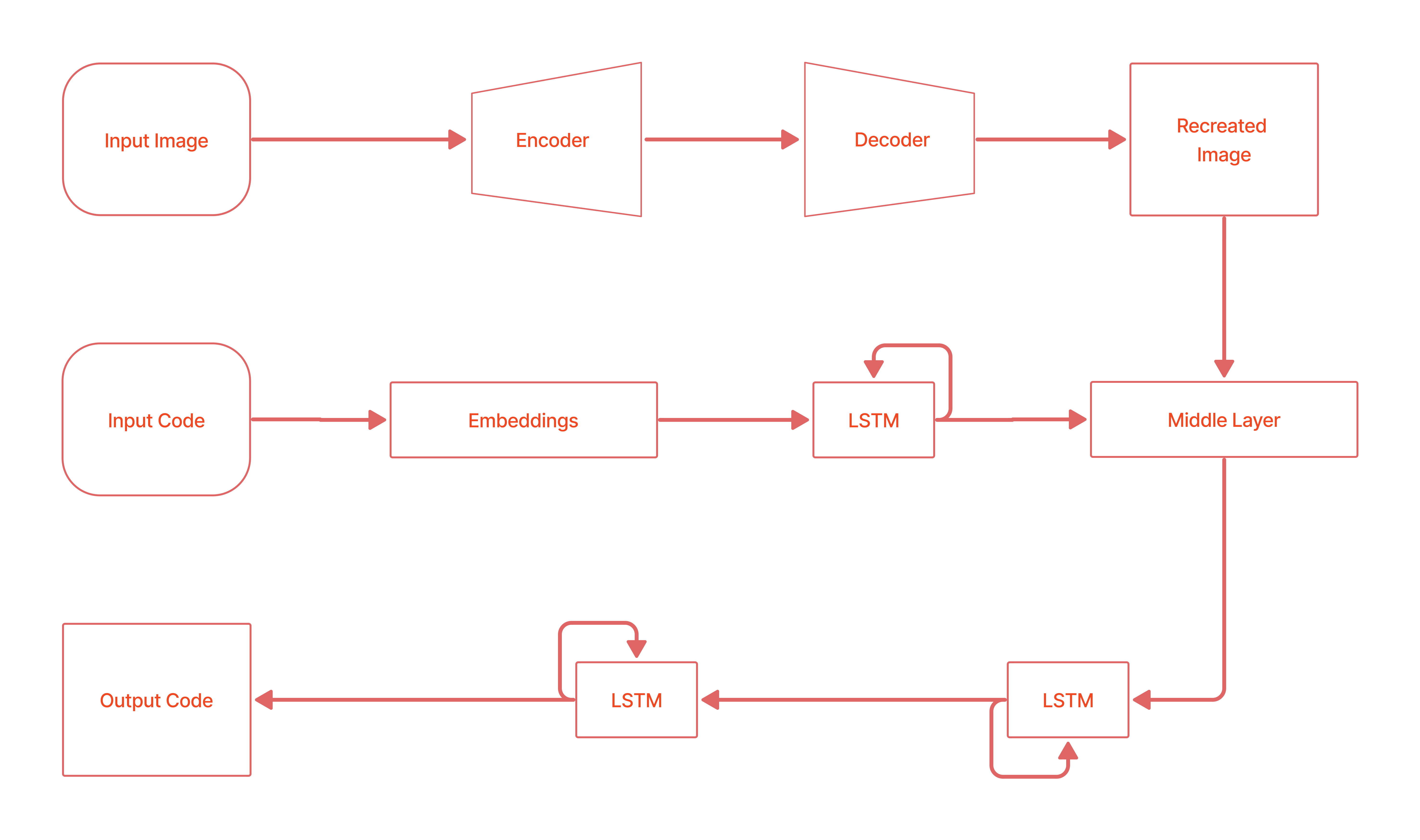 While training, the AI model receives the images which are passed to the
While training, the AI model receives the images which are passed to the Autoencoders and it is the first part of the whole model where it is pretrained on the images before the model learns about the code. The autoencoder learns the inner features and recreate the images but with lower dimension and transformed space representation. The second part of our model receives the input code for a mockup image in the form of an intermediate representation of actual code, DSL Code which is less intensive to the model in learning, feature mapping and helps in controlling the over-fitting problems which are then represented into embeddings, created by a sequential network. The learned parameters from autoencoder and the sequence network are concatenated in the middle layer which is then passed to a recurrent network that learn the parameters and mappings in between the image and the code. Apart from the autoencoder network, the rest of the model is what we called the Main_Model.
For trained model and weights if you need, drop me an email.
.
|── bin - contains the model pretrained weights in .h5 and .json
├── compiler - contains DSL compiler to HTML/bootstrap from intermediate code of .gui format
│ ├── assets - contains the asset of mappings needed for compiler
│ └── classes
├── datasets - contains dataset in zip files which is linked below in acknowledgement section
│ └── web
│ ├── all_data - will have the data with images and mockups when unziped
│ ├── eval_set - will have 250 pairs of images and mockups for evaluation
│ ├── training_set - will have 1500 pairs of images and mockups
│ └── training_features - will have 1500 of preprocessed images converted to numpy arrays
├── evaluate - evaluation of model based on BLEU scores
├── generated-outputs - contains the ouputs generated by the model
├── logs - logs of models
├── model - this is main working directory of the project
| └── classes
| ├── dataset - contains datasets generators
| └── model - contains the implementation of AI models
└── model-architectures - contains viualization of model architecture and thier summaries
Prepare the Dataset
# unzip the data
cd datasets
zip -F pix2code_datasets.zip --out datasets.zip
unzip datasets.zip
cd ../model
# split training set and evaluation set
# usage: build_datasets.py <input path>
./build_datasets.py ../datasets/web/all_data
# transform images into numpy arrays in training set (normalized pixel values and resized pictures to smaller files if you need to upload the set to train your model in the cloud)
# usage: convert_imgs_to_arrays.py <input path> <output path>
./convert_imgs_to_arrays.py ../datasets/web/training_set ../datasets/web/training_features
The dataset is split into two sets:
- Training :: 1500 pair of image and markups placed in
datasets/train/ - Evaluation :: 250 pair of image and markups placed in
datasets/eval/
Model Training
cd model
# provide input path to training data and output path to save trained model and metadata
# usage: train.py <input path> <output path> <train_autoencoder>
./train.py ../datasets/web/training_set ../bin
# train on images pre-processed as converted to numpy arrays
./train.py ../datasets/web/training_features ../bin
# train with autoencoder
./train.py ../datasets/web/training_features ../bin 1
Generate Code for an Image
mkdir generated-output
cd model
# generate DSL code aka the .gui file, the default search method is greedy
# usage: sample.py <trained weights path> <trained model name> <input image> <output path> <search method (default: greedy)>
./sample.py ../bin Main_Model ../test_gui.png ../generated-output
# equivalent to command above
./sample.py ../bin Main_Model ../test_gui.png ../code greedy
# generation with beam search is coming soon
Compile the .gui code to HTML
cd compiler
# compile .gui file to HTML code
# usage: web-compiler.py <input file path>.gui
./web-compiler.py ../generated-output/dot_gui.file