Ansible is a radically simple IT automation engine that automates cloud provisioning, configuration management, application deployment, intra-service orchestration, and many other IT needs.
-
Simple
- Human readable automation
- No special coding skills needed
- Tasks executed in order
- Get productive quickly
-
Powerful
- App deployment
- Configuration management
- Workflow orchestration
- Orchestrate the app lifecycle
-
Agentless
- Agentless architecture
- Uses OpenSSH and WinRM
- No agents to exploit or update
- Predictable, reliable and secure
- Human readable automation
- No special coding skills needed
- Tasks executed in order
- Get productive quickly
- App deployment
- Configuration management
- Workflow orchestration
- Orchestrate the app lifecycle
- Agentless architecture
- Uses OpenSSH and WinRM
- No agents to exploit or update
- Predictable, reliable and secure
https://docs.ansible.com/
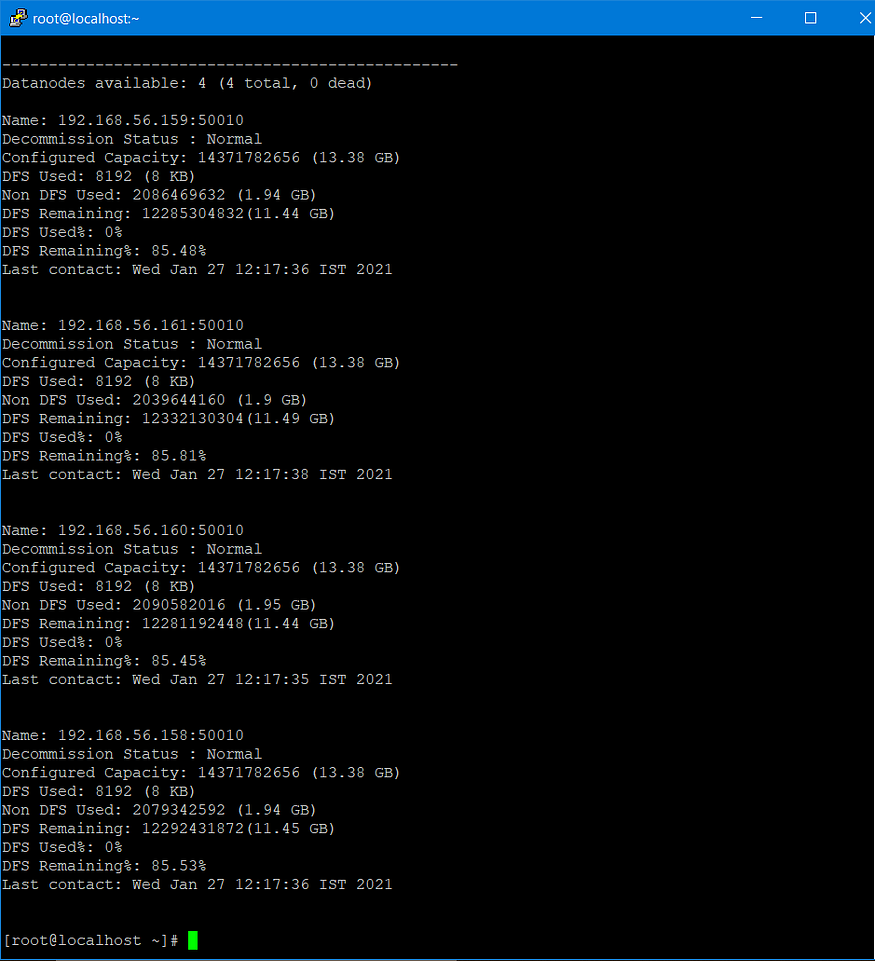
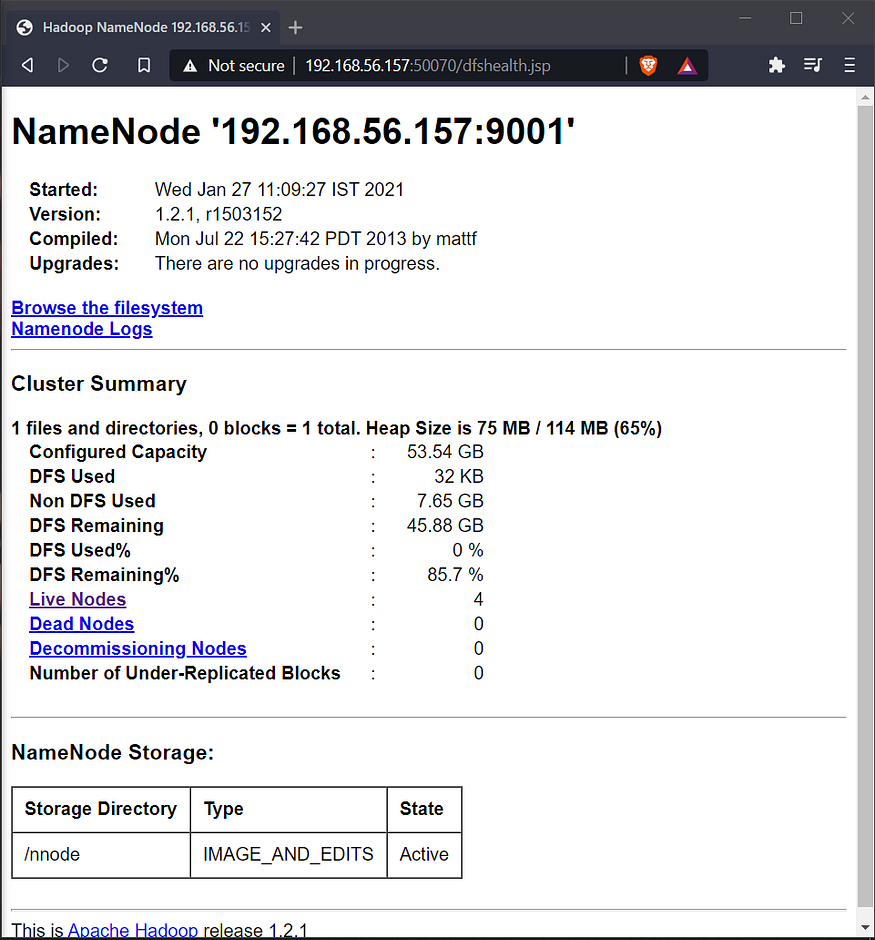
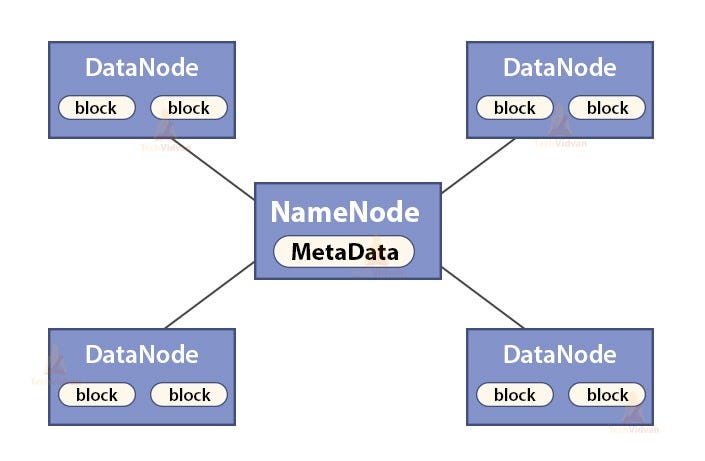
- Hadoop is the one of the software used for implementation of Distributed Storage and the topology used is one Master & multiple Slaves, and here protocol used between Master & Slave is known as HDFS(Hadoop Distributed File System) for file distribution among multiple file system.
- In Hadoop, Master Node is also known as NameNode whereas Slave Node is also known as DataNode, also cluster involving single node is known as Single Node Cluster whereas in case of Multiple Node Cluster, it involves multiple nodes.
For Hadoop Documentation, visit the link mentioned below:
https://hadoop.apache.org/docs/r1.2.1/
- JDK: 1.8.0_171
- Hadoop: 1.2.1
- Ansible: 2.9.11
- In main.yml, for both NameNode and DataNode, the change in Directory Creation executes the task(s) present within the handler.
- In case of NameNode, handlers stops the existing NameNode process, formats it and starts it again whereas in case of DataNode, the handler stops the existing DataNode process and starts it again.
- Also a Dummy Host has been created using "add_host" module to pass the NameNode's IP Address to the hosts acting as DataNode, as it needs to be specified in the DataNode's configuration file in order to set up the cluster.
- Template files for the configuration file of both NameNode and DataNode has been created. The files are hdfs-site.xml and core-site.xml respectively.
- For Playbook to be dynamic in nature, variable file i.e., vars.yml has been created that consist of variables namenode_dir and datanode_dir.
- Firewall and SELinux could be a hindrance for cluster setup using the above code, thereby it should be modified accordingly.
- The above code sets up the cluster which involves Single NameNode and Multiple DataNodes.
- More DataNodes could be added easily using the above code.