This repository contains a PyTorch implementation of the Stochastic Weight Averaging (SWA) training method for DNNs from the paper
Averaging Weights Leads to Wider Optima and Better Generalization
by Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov and Andrew Gordon Wilson.
Note: as of August 2020, SWA is now a core optimizer in the PyTorch library, and can be immediately used by anyone with PyTorch, without needing an external repo, as easily SGD or Adam. Please see this blog post introducing the native PyTorch implementation with examples.
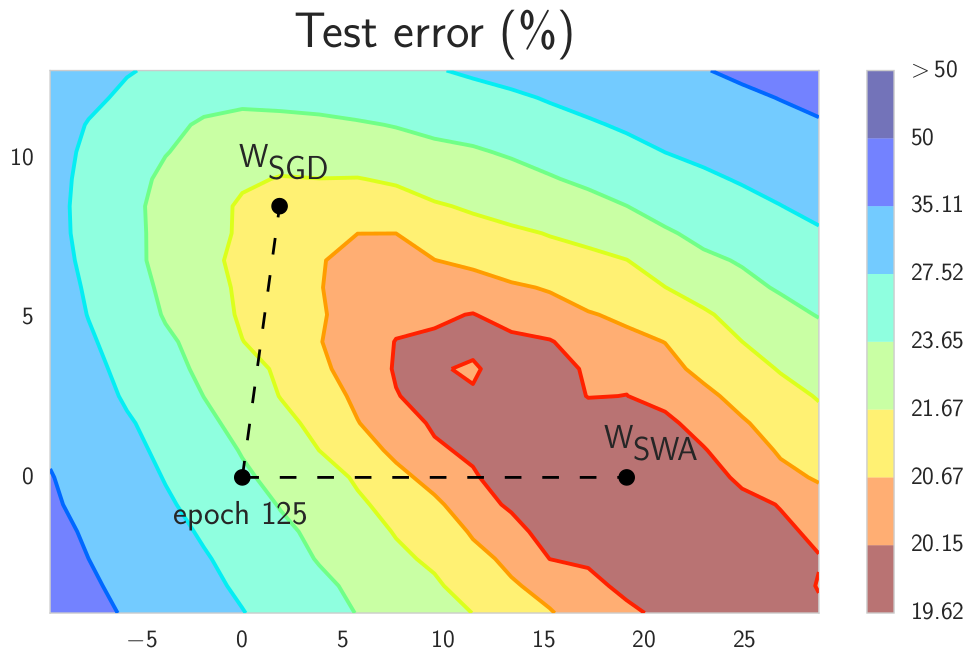
SWA is a simple DNN training method that can be used as a drop-in replacement for SGD with improved generalization, faster convergence, and essentially no overhead. The key idea of SWA is to average multiple samples produced by SGD with a modified learning rate schedule. We use a constant or cyclical learning rate schedule that causes SGD to explore the set of points in the weight space corresponding to high-performing networks. We observe that SWA converges more quickly than SGD, and to wider optima that provide higher test accuracy.
In this repo we implement the constant learning rate schedule that we found to be most practical on CIFAR datasets.


Please cite our work if you find this approach useful in your research:
@article{izmailov2018averaging,
title={Averaging Weights Leads to Wider Optima and Better Generalization},
author={Izmailov, Pavel and Podoprikhin, Dmitrii and Garipov, Timur and Vetrov, Dmitry and Wilson, Andrew Gordon},
journal={arXiv preprint arXiv:1803.05407},
year={2018}
}The code in this repository implements both SWA and conventional SGD training, with examples on the CIFAR-10 and CIFAR-100 datasets.
To run SWA use the following command:
python3 train.py --dir=<DIR> \
--dataset=<DATASET> \
--data_path=<PATH> \
--model=<MODEL> \
--epochs=<EPOCHS> \
--lr_init=<LR_INIT> \
--wd=<WD> \
--swa \
--swa_start=<SWA_START> \
--swa_lr=<SWA_LR>Parameters:
DIR— path to training directory where checkpoints will be storedDATASET— dataset name [CIFAR10/CIFAR100] (default: CIFAR10)PATH— path to the data directoryMODEL— DNN model name:- VGG16/VGG16BN/VGG19/VGG19BN
- PreResNet110/PreResNet164
- WideResNet28x10
EPOCHS— number of training epochs (default: 200)LR_INIT— initial learning rate (default: 0.1)WD— weight decay (default: 1e-4)SWA_START— the number of epoch after which SWA will start to average models (default: 161)SWA_LR— SWA learning rate (default: 0.05)
To run conventional SGD training use the following command:
python3 train.py --dir=<DIR> \
--dataset=<DATASET> \
--data_path=<PATH> \
--model=<MODEL> \
--epochs=<EPOCHS> \
--lr_init=<LR_INIT> \
--wd=<WD> To reproduce the results from the paper run (we use same parameters for both CIFAR-10 and CIFAR-100 except for PreResNet):
#VGG16
python3 train.py --dir=<DIR> --dataset=CIFAR100 --data_path=<PATH> --model=VGG16 --epochs=200 --lr_init=0.05 --wd=5e-4 # SGD
python3 train.py --dir=<DIR> --dataset=CIFAR100 --data_path=<PATH> --model=VGG16 --epochs=300 --lr_init=0.05 --wd=5e-4 --swa --swa_start=161 --swa_lr=0.01 # SWA 1.5 Budgets
#PreResNet
python3 train.py --dir=<DIR> --dataset=CIFAR100 --data_path=<PATH> --model=[PreResNet110 or PreResNet164] --epochs=150 --lr_init=0.1 --wd=3e-4 # SGD
#CIFAR100
python3 train.py --dir=<DIR> --dataset=CIFAR100 --data_path=<PATH> --model=[PreResNet110 or PreResNet164] --epochs=225 --lr_init=0.1 --wd=3e-4 --swa --swa_start=126 --swa_lr=0.05 # SWA 1.5 Budgets
#CIFAR10
python3 train.py --dir=<DIR> --dataset=CIFAR10 --data_path=<PATH> --model=[PreResNet110 or PreResNet164] --epochs=225 --lr_init=0.1 --wd=3e-4 --swa --swa_start=126 --swa_lr=0.01 # SWA 1.5 Budgets
#WideResNet28x10
python3 train.py --dir=<DIR> --dataset=CIFAR100 --data_path=<PATH> --model=WideResNet28x10 --epochs=200 --lr_init=0.1 --wd=5e-4 # SGD
python3 train.py --dir=<DIR> --dataset=CIFAR100 --data_path=<PATH> --model=WideResNet28x10 --epochs=300 --lr_init=0.1 --wd=5e-4 --swa --swa_start=161 --swa_lr=0.05 # SWA 1.5 BudgetsTest accuracy (%) of SGD and SWA on CIFAR-100 for different training budgets. For each model the Budget is defined as the number of epochs required to train the model with the conventional SGD procedure.
| DNN (Budget) | SGD | SWA 1 Budget | SWA 1.25 Budgets | SWA 1.5 Budgets |
|---|---|---|---|---|
| VGG16 (200) | 72.55 ± 0.10 | 73.91 ± 0.12 | 74.17 ± 0.15 | 74.27 ± 0.25 |
| PreResNet110 (150) | 76.77 ± 0.38 | 78.75 ± 0.16 | 78.91 ± 0.29 | 79.10 ± 0.21 |
| PreResNet164 (150) | 78.49 ± 0.36 | 79.77 ± 0.17 | 80.18 ± 0.23 | 80.35 ± 0.16 |
| WideResNet28x10 (200) | 80.82 ± 0.23 | 81.46 ± 0.23 | 81.91 ± 0.27 | 82.15 ± 0.27 |
Below we show the convergence plot for SWA and SGD with PreResNet164 on CIFAR-100 and the corresponding learning rates. The dashed line illustrates the accuracy of individual models averaged by SWA.

Test accuracy (%) of SGD and SWA on CIFAR-10 for different training budgets.
| DNN (Budget) | SGD | SWA 1 Budget | SWA 1.25 Budgets | SWA 1.5 Budgets |
|---|---|---|---|---|
| VGG16 (200) | 93.25 ± 0.16 | 93.59 ± 0.16 | 93.70 ± 0.22 | 93.64 ± 0.18 |
| PreResNet110 (150) | 95.03 ± 0.05 | 95.51 ± 0.10 | 95.65 ± 0.03 | 95.82 ± 0.03 |
| PreResNet164 (150) | 95.28 ± 0.10 | 95.56 ± 0.11 | 95.77 ± 0.04 | 95.83 ± 0.03 |
| WideResNet28x10 (200) | 96.18 ± 0.11 | 96.45 ± 0.11 | 96.64 ± 0.08 | 96.79 ± 0.05 |
- Chainer Implementation: github.com/chainer/models/tree/master/swa
- Keras/Tensorflow-Keras Implementation: github.com/simon-larsson/keras-swa
- PyTorch Contrib: github.com/pytorch/contrib
Provided model implementations were adapted from
- VGG: github.com/pytorch/vision/
- PreResNet: github.com/bearpaw/pytorch-classification
- WideResNet: github.com/meliketoy/wide-resnet.pytorch