Modeling Data
Data modeling is the process of mapping your data to an ontology so that Karma can integrate it with data from other sources and publish it in a new format. To model your data you need to first import your data and the ontologies you want to use to model your data (see Importing Data).
If you have not defined a model for this source yet, Karma will show an empty model as indicated by the small red circles above each column heading:
![]()
The modeling process consists of the following activities:
As you continue modeling, Karma provides suggestions for semantic types and an automatic alignment feature that suggests relations between classes. If you want to disable this automatic alignment feature, you should change:
{KARMA_USER_HOME}\config\modeling.properties and set:
ontology.alignment=false
knownmodels.alignment=false
A semantic type defines the relationship between a column of data and a property and a class in your ontology.
For example, in the artworks-list.xml data shown above, we want specify that the artist column contains the names of people.
We can do this by mapping the artist column to the foaf:name of a foaf:Person
(foaf is a popular ontology for modeling data about people http://xmlns.com/foaf/spec/).
Karma is ontology agnostic, so you can use whatever ontology you want to model your data.
To specify a semantic type, mouse over the red dot on top of the column heading. A Suggest button appears. Click on the Suggest button. It shows all recommendations available for the column.
 Click on the checkbox next to the correct semantic type. If none of the suggestions are correct, you can click on the link label of the
Click on the checkbox next to the correct semantic type. If none of the suggestions are correct, you can click on the link label of the Empty semantic type and change it first, followed by clicking on the Empty node and changing the node.
![]()
Semantic types can be specified in several different ways and can combine multiple pieces of information. We explain each of these in turn:
- Basic semantic types
- Editing suggestions
- Multiple semantic types for a column
- Multiple columns with the same semantic type
- URIs for classes
- Literal types
The most common way of constructing a semantic type is to define it based on a property and a class in your ontology.
When you use Karma on multiple data sources related to the same domain (e.g., several data sources with data about museums), Karma will learn the semantic types you assign to data, and offer them as suggestions.
In this example, we had been using Karma to model several museum sources so Karma shows the top-ranked suggestions for the semantic type for the artist column.
Click on the check box to select foaf:name of foaf.Person1 and click submit to assign it.
Karma updates the model to show your semantic type assignment:

Sometimes, the suggested semantic types are not exactly what you want.
In these cases, you can click on the Empty semantic type and change the class, followed by clicking on the label link and changing it.
![]() .
.
The modification can be done in any order. Clicking on the link brings up this UI:

The dialog lists all properties and you can click on them to select the required property. Karma also offers type-in completion to narrow the results.

Clicking on the node with no name will open up the Class Dialog where you can choose the appropriate class for the type.

Once a semantic type is chosen for a column, Karma will learn the new type and offer it as a suggestion for similar columns.
The empty nodes can also be dragged and dropped into existing nodes to modify the links and then you can click on the link to change it.

Often you may want to assign multiple semantic types to a column.
For example, you may want to model the artist column as the foaf:name of a foaf:Person and you also want to model it as the rdfs:label as the name is an appropriate label for people (it is good practice to define an rdfs:label for all classes in your models).
To do this, you can create a duplicate of the column artist_copy and set the semantic type of artist-copy as rdfs:label of foaf-Person.
Click on artist and select PyTranform. Enter the name of the column as artist_copy and then click Save.

This will create a column artist_copy with the same value as artist. Now, click on Suggest button when you mouse over the red dot for artist_copy. It shows the following suggestions:
 .
.
Click on the name of the link from Person1 to artist_copy and change it to rdfs:label. This is what the model looks like:

Sometimes you have a situation where a source contains two columns with the same type of data, but the data in one column refers to different individuals than the data in the other column.
For example, consider the following dataset containing data about artworks.
The Artist column contains the name of the creator of the artwork so we modeled it as the name of a foaf:Person1.
The Sitter column also contains the names of people, but these are the names of the people depicted in the artwork.

It is important for the model to specify that the artist and the sitter are different people.
This is what the indices after the class names are for (e.g., the 1 in Person1).
If the artist is Person1, we want the sitter to be a different person, say Person2.
To do this, click on the Suggest button as you mouse over Sitter to see the semantic suggestions for sitter.

Click on the link of the empty suggestion and change it to foaf:name as shown below:
 .
.
Now click on the empty node/class and select foaf:Person2 (add).
 .
.
This is how the semantic type for sitter finally looks like:
 .
.
Now, to build on the model to show the relationship between Person1 and Person2, we can build the final model where we define a CulturalHeritageObject node, whose creator is Person1 and whose sitter is Person2 as shown below:

See Specifying relationships among classes for details on how to specify the relationships between Person1, CulturalHeritageObject1 and Person2
Every bubble in your model represents a class of entities in the world.
For example, Person1 in the following model represents the class of artists.
Different records in your dataset typically represent different specific entities.
For example, in the first row, Frishmuth, Harriet Whitney is the name of one artist, and Archipenko, Alexander is the name of a different artist:

When we model datasets, we typically want to assign unique identifiers to each entity mentioned in a dataset so that we can refer to them later when we publish the data. This is especially important when we have multiple datasets that refer to the same individual and we want to make sure that the data is cross-refenced appropriately so that we can merge the data about the same individuals when they are mentioned in different datasets. For example, we may have an "artworks" dataset that tells us that Alexander Archipenko created the bronze statue titled Concave of Standing Woman, and we may have an "artists" dataset that tell us that he was born in Kiev. We want our models to define a unique identifier to Alexander Archipenko so that all the data about him is tied to the same identifier.
If you want absolute control over the URIs for entities, you can store them in a column in your dataset and tell Karma to use those URIs for the entities in your class.
The following screenshot shows our "artworks" dataset transformed using PyTransform to add a column that explicitly provides the URI that we should use for each artist:

To tell Karma to use the URIs in column artist_uri as the URIs for Person1, click on Suggest button for artist_uri:

Click on the link label from artist_uri to Person1. This bring up this dialog:
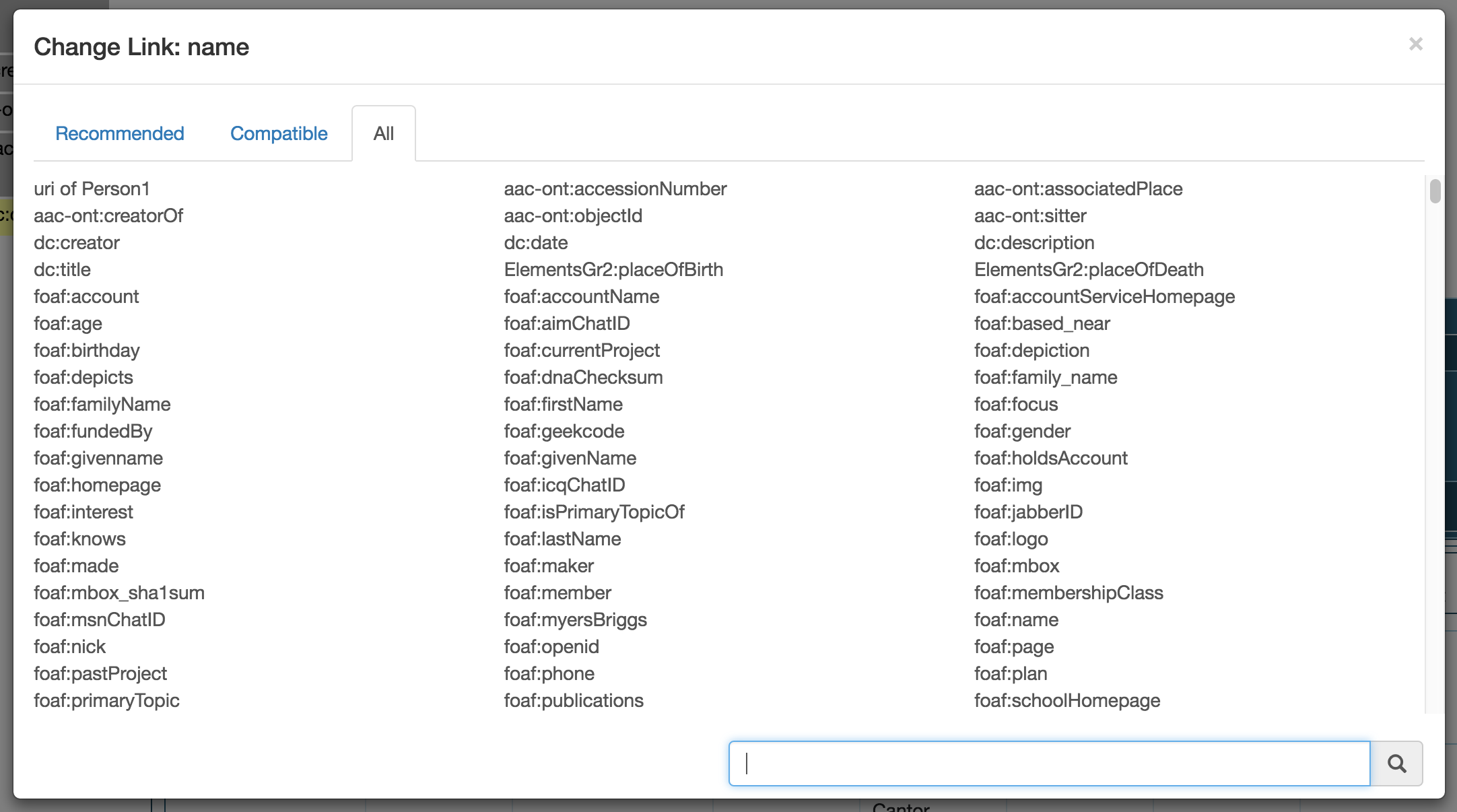
Choose the first option - uri of Person1.
Karma will update the model. The label uri shows that a column is being used to specify the URI for a class.

When you publish the data in RDF, Karma will use the URIs you specify to define the URIs for your entities.
For example, the URI for Alexander Archipenko will be http://ima.org/people/Alexander_Archipenko.
Note: if your model has a class for which you don't specify a URI, then Karma will generate a blank node for it. All the data within a single dataset will be self consistent, but there will be now way to cross-reference the entities in that class with entities in the same class in other datasets. It makes sense to use blank nodes for classes that you use to group information together, but which don't correspond to an entity in the world.
You can explicitly define the types of literals. To do so, click on a name link of Person1. This brings up this dialog:
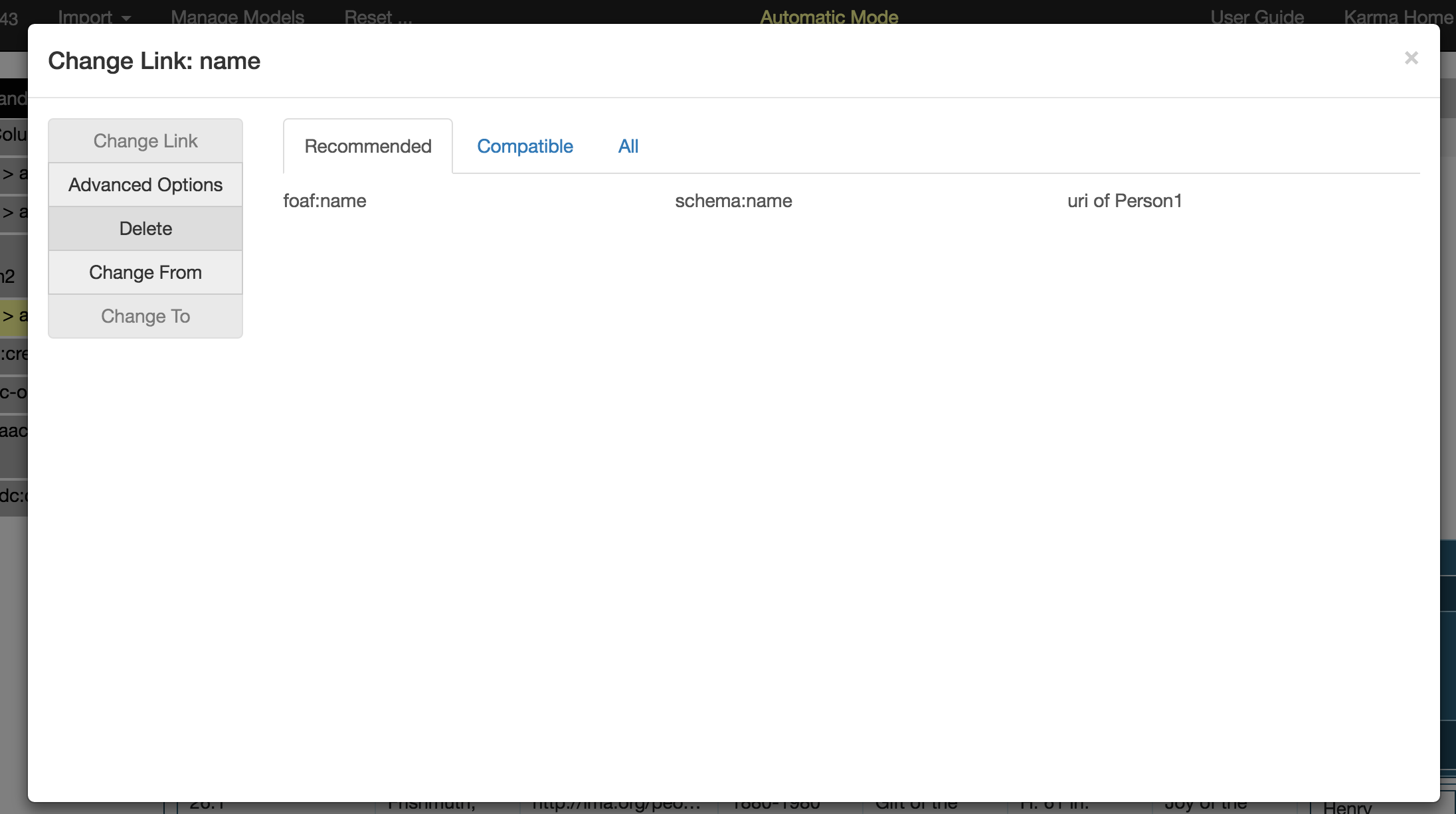
Now, click on the Advanced Options menu button from the left panel. This brings up the UI to specify the Literal Type. Karma offers the standard XSD types in a menu and also allows you to enter your own URIs if that is appropriate for your application.

We start with the following model for the artist and sitter of an artwork:
.
We need to specify the relationship between Person1 and Person2, which we can by defining a CulturalHeritageObject node, whose creator is Person1 and whose sitter is Person2
To generate that model, mouse over the red dot of Person1 and click on the Suggest button.

If there are no suggestions, the UI shows an empty incoming and outgoing link. Click on the link label of the empty incoming link, and change it to creator as shown below

Now click on the empty node of this link and change the class to be CulturalHeritageObject1. Below is the resulting model:
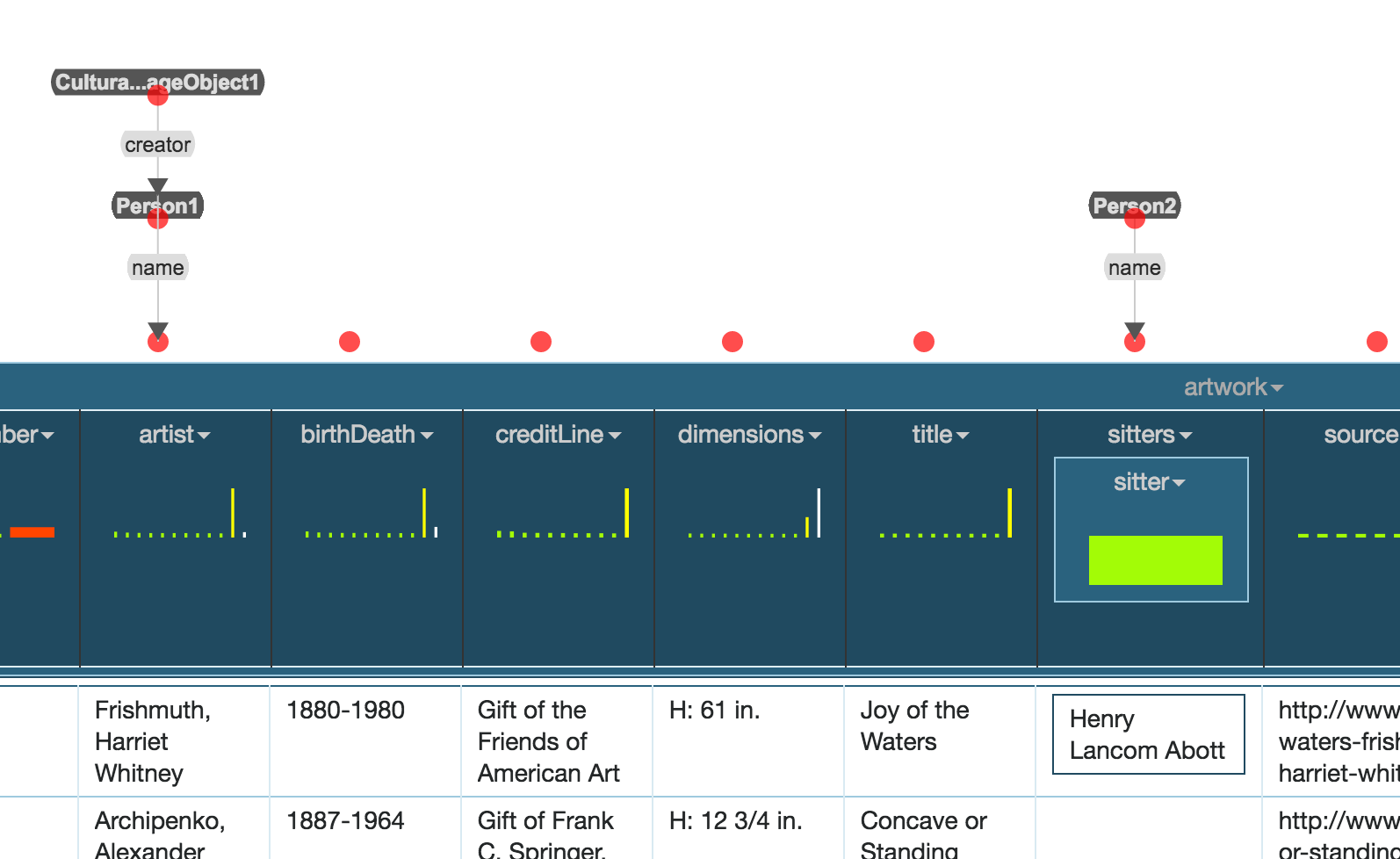
Now, to connect Person2 to CulturalHeritageObject1, click on the Suggest button for Person2.

Change the empty incoming link to be sitter

Now drag the empty node of this link by its red dot and drop it into CulturalHeritageObject1. This produces the final model:
The model contains two person bubbles: Person1 for the artist and Person2 for the sitter.
Both columns contains the names, so we used the foaf:name property in both semantic types.
The other bubble, CulturalHeritageObject1 represents the artwork and the creator and sitter links represent the relationships between the artwork and the people.