ml_monitor package introduces an effortless monitoring of a machine learning training process. It also provides some useful stats about the resources utilization out of the box. And most important - it is designed for an easy integration with not only Jupyter, but also Google Colab notebooks.

- python >= 3.6
- docker
- Clone and enter the repository
git clone https://github.com/wiatrak2/ml_monitor.git
cd ml_monitor-
Run
python configure_gdrive.pyto configure Google Drive API, which is required for Colab integration. You need to create a project and enter its credentials -client_idandclient_secret. There are two ways obtain them:- Go to Google Drive API python tutorial and click Enable the Drive API. This will create a new project named Quickstart that is already properly configured. You will see a window with
Client IDandClient Secret, thatconfigure_gdrive.pyis asking you for. - If you want to create a new project for
ml_monitoryou need to go to the Google API Console and:- Open Select a project menu (next to the Google APIs logo) and click New project
- Set the project name, create it and enter
- Search for the
Google Drive APIand click Enable - From the left sidebar select Credentials
- If you see a Configure Consent Screen button click it and fill the form (entering the Application name is enough). Then click Create credentials and select OAuth Client ID, select Other from the next view and process
- You will see a window with
Client IDandClient secret. Paste them to theconfigure_gdrive.py
- Go to Google Drive API python tutorial and click Enable the Drive API. This will create a new project named Quickstart that is already properly configured. You will see a window with
-
Install package using
pip
pip install .Please note that GIFs have not been adjusted to the latest release yet
There are two components responsible for a successful monitoring of your training. First of them is a thread that collects metrics inside your notebook or python program. The second is a process that makes use of these metrics, parses them and enables things like a pretty visualization. These seemingly complex tasks are implemented to make usage as easy as possible - let's have a look:
dockerdirectory contains an easy setup of tools used for metrics visualization and analysis. These are Prometheus and Grafana. You should firstly start these programs, withdocker-compose upcommand. Now you should be able to reach the Grafana admin panel on http://localhost:3000. Default credentials areusername: adminandpassword: ml_monitor. Also a Prometheus UI should be reachable on http://localhost:9090. You can learn some basics about the Prometheus and it's features here.- Alright, let's start the monitoring! How to launch the
ml_monitorinside your notebook? All you need is:
import ml_monitor
my_monitor = ml_monitor.Monitor()
my_monitor.start()- Really, it's enough. The
my_monitorobject is your gateway to the whole monitoring system. Now there is a background thread managed by themy_monitorobject, that is collecting your metrics and periodically stores them, so other components are able to make use of these values. This thread will handle your custom metrics when you set them withmy_monitor.monitor("foo", 42.0)- now the collector thread stores a metric namedfoowith value42.0. Withhooksmechanism you can continuously monitor things like e.g. CPU utilization - there already isml_monitor.UtilizationHookclass that adds this data to the collected metrics. To apply this hook just runmy_monitor.register_hook(ml_monitor.UtilizationHook()) - Metrics are already collected, let's use them. From the directory where your notebook is stored run
pythoninterpreter and start the mechanism that I calledcontrol, as it manages all the metrics etc. To start parsing the metrics collected by your local notebook use:
import ml_monitor
ml_monitor.control.start()- You are ready. Go to the Grafana web app and have the training under control. To discover how to make use of the metrics learn more about PromQL.
Following these steps will let you use the package from the very scratch. I believe that there should be as little required code lines to setup a tool as possible. Therefore, you don't have to modify your already working code to extend it with the ml_monitor.
- To finish the
ml_monitor.controland terminate the running threads useml_monitor.control.stop().
Google Colab notebooks let's you run your code using some top GPUs and even TPU for free. It is a great and essential tool for many ML developers. When the ml_monitor project was started, it main purpose was to provide a mechanism to follow any desired metrics real time. Therefore ml_monitor allows you to begin the integration with Google Colab as easy as in local Jupyter notebook approach.
Parsing and visualization of all the metrics is again done on your local machine. As code executed by Colab notebooks is separated from your device it is a bit more complicated to have a synchronized data collected by ml_monitor inside the Google Colab notebook. Fortunately, you can easily mount your Google Drive and use it within the notebook. Moreover, ml_monitor implements a simple file system to enable communication with your Google Drive. Therefore, during the training, metrics collected with ml_monitor are stored on your Google Drive, and ml_monitor.colab.control that runs on your local machine can fetch them. All the details are configurable, but the default configuration is enough to use all the ml_monitor features.
To start monitoring your Google Colab notebook you should:
- Start the
ml_monitor.colab.control, that will fetch the metrics from your Google Drive and process them for tools like Grafana and Docker. It is done once again with a single command:
import ml_monitor
ml_monitor.colab.control()- During the first usage you will be asked for a verification code, so the
ml_monitorcould communicate with your Google Drive. Your browser will (and should) complain about security aspects, but you can still obtain the code and grant theml_monitoraccess to your files. It is necessary, as this is the only way to collect the metrics produced by your Colab notebook.

- Open your Colab notebook and start monitoring with:
import ml_monitor
my_colab_monitor = ml_monitor.colab.ColabMonitor()
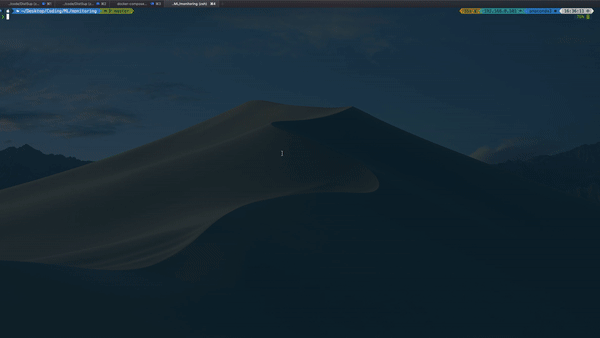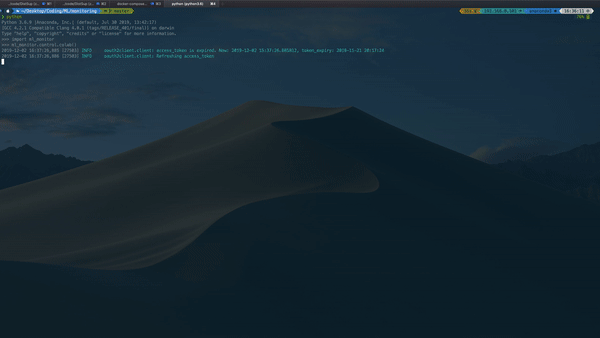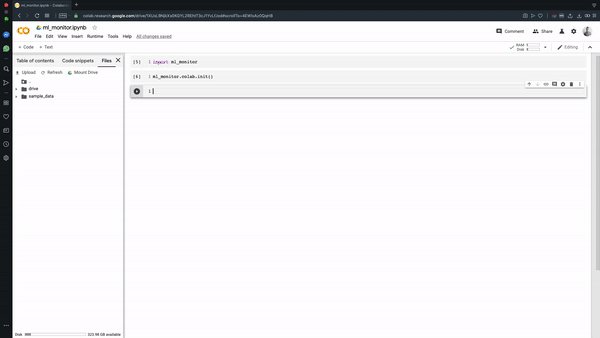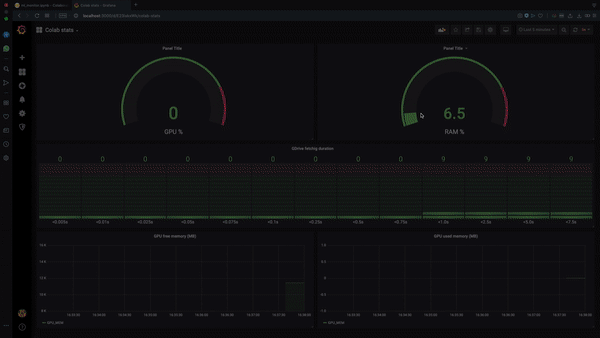
my_colab_monitor.start()- That's it. As easy as previously. Moreover you can find a pre-defined Grafana dashboard Colab stats that presents statistics like GPU utilization, RAM usage or how long it took to fetch the metrics from your Google Drive to your local machine.
- To finish the
ml_monitor.controland terminate the running threads useml_monitor.control.stop().
Collecting metrics, like value of a loss function, should not require changes in already working code. Also you should be made to add as few lines of code as possible. Therefore, if you want to monitor a metric called some_stat and set its value as 0.123, all you have to do is call the monitor method on your Monitor/ColabMonitor object:
my_colab_monitor.monitor("some_stat", 0.123)This metric should be afterwards visible i.e. on Prometheus UI (http://localhost:9090/graph) and charted with Grafana. some_stat will have assigned value 0.123 as long as it will be changed manually, like:
my_colab_monitor.monitor("some_stat", 123.0)You can call the monitor function the same way from both local code and Google Colab.

Metrics defined within python code are collected with usage of Prometheus Pushgateway. You may noticed that they are described with exported_job label, which is by default ml_monitor or colab_ml_monitor. The exported_job label could be used to easily filter values (e.g. losses) from specific training process. Therefore ml_monitor allows you to set the exported_job with ml_monitor.set_training(training_name: str) function:
...
my_colab_monitor.set_training("colab_ResNet_50")
...
for i in range(epochs):
...
my_colab_monitor.monitor("loss", loss.item())
my_colab_monitor.monitor("epoch", i)
...You should be then able to filter values from this training using PromQL and curly braces{} :
loss{exported_job="colab_ResNet_50"}

- If during launching
ml_monitor.control.colab()or some other mechanism that may be using the Google Drive API you get thegoogleapiclient.errors.HttpError: <HttpError 403 when requesting https://www.googleapis.com/drive/...error, theml_monitormay be trying to authenticate with expired credentials. Check if your current directory containscredentials.jsonand remove it.
The ml_monitor package is during development, and this is a very alpha version 😄 I hope somebody will find it helpful during long, lonely model training sessions 💻