深度学习系列3 - CNNs 以及应对过拟合的详细探讨 #2026
Conversation
|
@sqrthree 校对认领 |
|
@lileizhenshuai 好的呢 🍺 |
|
|
||
| *This post is part of a series on deep learning. Check-out *[*part 1*](https://medium.com/towards-data-science/deep-learning-1-1a7e7d9e3c07)* and *[*part 2*](https://medium.com/towards-data-science/deep-learning-2-f81ebe632d5c)*.* | ||
| > 这篇文章是深度学习系列中一篇文章。请查看[#系列1](https://medium.com/towards-data-science/deep-learning-1-1a7e7d9e3c07)和[#系列2](https://medium.com/towards-data-science/deep-learning-2-f81ebe632d5c) |
There was a problem hiding this comment.
There was a problem hiding this comment.
不用,直接用我们 repo 内的链接即可。第一篇的地址:https://github.com/xitu/gold-miner/blob/master/TODO/deep-learning-1-setting-up-aws-image-recognition.md
|
|
||
|  | ||
|
|
||
| Data augmentation is of the techniques in reducing overfitting | ||
| Welcome to the third entry in this series on deep learning! This week I will explore some more parts of the Convolutional Neural Network (CNN) and will also discuss how to deal with underfitting and overfitting. | ||
| 数据增强(Data augmentation)是一种减少过拟合的方式。欢迎来到本系列教程的第三部分的学习!这周我会讲解一些` CNN `的内容并且讨论如何解决`欠拟合`和`过拟合`。 |
There was a problem hiding this comment.
数据增强(Data augmentation)是一种减少过拟合的方式。欢迎来到本系列教程的第三部分的学习! ->
数据增强(Data augmentation)是一种减少过拟合的方式。
欢迎来到本系列教程的第三部分的学习!
第一句话是对图片的解释吧?可能加个回车更好一点
|
|
||
| So what exactly is a convolution? As you might remember from my previous blog entries we basically take a small filter and slide this filter over the whole image. Next, the pixel values of the image are multiplied with the pixel values in the filter. The beauty in using deep learning is that we do not have to think about how these filters should look. Through Stochastic Gradient Descent (SGD) the network is able to learn the optimal filters. The filters are initialized at random and are location-invariant. This means that they can find something everywhere in the image. At the same time the model also learns where in the image it has found this thing. | ||
| 那么究竟什么是卷积呢?你可能还记得我之前的博客,我们使用了一个小的滤波器(filter),并在整个图像上平滑移动这个滤波器。然后,将图像的像素值与滤波器中的像素值相乘。使用深度学习的优雅之处在于我们不必考虑这些滤波器应该是什么样的 —— 神经网络会自动学习并选取最佳。通过随机梯度下降(SGD),网络能够自主学习从而达到最优。滤波器被随机初始化,并且位置不变。这意味着他们可以在图像中找到任何物体。同时,该模型还能学习到是在这个图像的哪个位置找到这个物体。 |
|
|
||
| When we slide these filters over our image we basically create another image. Therefore, if our original image was 30x30 the output of a convolutional layer with 12 filters will be 30x30x12. Now we have a tensor, which basically is a matrix with over 2 dimensions. Now you also know where the name TensorFlow comes from. | ||
| 滤波器(filter)可以看做 CNN的核心,从信号处理的角度而言,滤波器是对信号做频率筛选,这里主要是空间-频率的转换,CNN 的训练就是找到最好的滤波器使得滤波后的信号更容易分类,还可以从模版匹配的角度看卷积,每个卷积核都可以看成一个特征模版,训练就是为了找到最适合分类的特征模版 |
There was a problem hiding this comment.
滤波器(filter)可以看做 CNN的核心 -> 滤波器(filter)可以看做 CNN 的核心
|
|
||
|  | ||
| 当我们将这些滤波器依次滑过图像时,我们基本上创建了另一个图像。因此,如果我们的原始图像是30 x 30,则带有12个滤镜的卷积层的输出将为30 x 30 x 12。现在我们有一个张量,它基本上是一个超过2维的矩阵。现在你也就知道TensorFlow的名字从何而来。 |
|
|
||
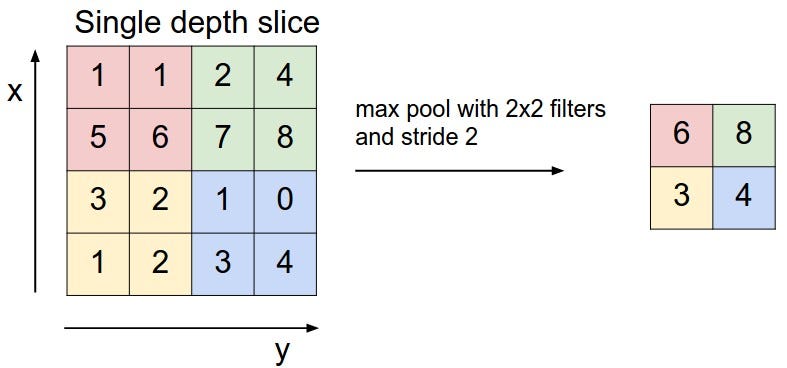
| After each convolutional layer (or multiple) we typically have a max pooling layer. This layer simply reduces the amount of pixels in the image. For example, we can take a square of our image and replace this with only the highest value on the square. | ||
| 零填充是应用此滤波器时的有用工具。这些都是在图像周围的零像素的额外边框 —— 这允许我们在将滤镜滑过图像时捕获图像的边缘。你可能想知道滤波器应该多大,研究表明,较小的滤波器通常表现更好。在这个例子当中,我们使用大小为3x3的滤波器。 |
There was a problem hiding this comment.
这句话的原文我也理解了很久,当时没理解透彻,回头我再查一点资料,尝试换一种详细点的方式解释。
|
|
||
| Max Pooling | ||
| Because of Max Poling our filters can explore bigger parts of the image. Additionally, because of the loss in pixels we typically increase the number of filters after used max pooling. | ||
| 在每个卷积层(或多个)之后,我们通常就得到了最大池层。这个层会减少图像中的像素数量。例如,我们可以从图像中取出一个正方形然后用这个这个正方形里面的最大值代替这个正方形。(如下图所示) |
There was a problem hiding this comment.
正方形然后用这个这个正方形里面的最大值代替这个正方形 ->
正方形然后用这个这个正方形里面像素的最大值代替这个正方形
|  | ||
|
|
||
| 得益于 `Max Poling`,我们的滤波器可以探索图像的较大部分。另外,由于像素损失,我们通常会增加使用最大池化后的滤波器数量。 | ||
| 理论上来说,每个模型架构都可以工作并且为你的的问题提供一个很好的解决方案。然而,一些架构比其他架构要快得多。一个很差的架构可能需要超过你剩余生命的时间来得出结果。因此,考虑你的模型的架构以及我们为什么使用最大池并改变所使用的滤波器的数量是有意义的。为了在 CNN 上完成这个部分,[这个](http://yosinski.com/deepvis#toolbox)页面提供了一个很好的视频,可以将发生在 CNN 内部的事情可视化。 |
|
|
||
| How do you know if your model is underfitting? Your model is underfitting if the accuracy on the validation set is higher than the accuracy on the training set. Additionally, if the whole model performs bad this is also called underfitting. For example, using a linear model for image recognition will generally result in an underfitting model. Alternatively, when experiencing underfitting in your deep neural network this is probably caused by dropout. Dropout randomly sets activations to zero during the training process to avoid overfitting. This does not happen during prediction on the validation/test set. If this is the case you can remove dropout. If the model is now massively overfitting you can start adding dropout in small pieces. | ||
| 你如何知道你的模型是否欠拟合? 如果你的验证集的准确度高于训练集,那就是模型欠拟合。此外,如果整个模型表现得不好,也会被称为欠拟合。例如,使用线性模型进行图像识别通常会出现欠拟合的结果009。也有可能是因为`dropout`的原因导致你在深层神经网络中遇到欠拟合的情况。 |
|
|
||
| How do you know if your model is underfitting? Your model is underfitting if the accuracy on the validation set is higher than the accuracy on the training set. Additionally, if the whole model performs bad this is also called underfitting. For example, using a linear model for image recognition will generally result in an underfitting model. Alternatively, when experiencing underfitting in your deep neural network this is probably caused by dropout. Dropout randomly sets activations to zero during the training process to avoid overfitting. This does not happen during prediction on the validation/test set. If this is the case you can remove dropout. If the model is now massively overfitting you can start adding dropout in small pieces. | ||
| 你如何知道你的模型是否欠拟合? 如果你的验证集的准确度高于训练集,那就是模型欠拟合。此外,如果整个模型表现得不好,也会被称为欠拟合。例如,使用线性模型进行图像识别通常会出现欠拟合的结果009。也有可能是因为`dropout`的原因导致你在深层神经网络中遇到欠拟合的情况。 |
There was a problem hiding this comment.
也有可能是因为dropout的原因 ->
也有可能是因为 dropout 的原因
|
|
||
| How do you know if your model is underfitting? Your model is underfitting if the accuracy on the validation set is higher than the accuracy on the training set. Additionally, if the whole model performs bad this is also called underfitting. For example, using a linear model for image recognition will generally result in an underfitting model. Alternatively, when experiencing underfitting in your deep neural network this is probably caused by dropout. Dropout randomly sets activations to zero during the training process to avoid overfitting. This does not happen during prediction on the validation/test set. If this is the case you can remove dropout. If the model is now massively overfitting you can start adding dropout in small pieces. | ||
| 你如何知道你的模型是否欠拟合? 如果你的验证集的准确度高于训练集,那就是模型欠拟合。此外,如果整个模型表现得不好,也会被称为欠拟合。例如,使用线性模型进行图像识别通常会出现欠拟合的结果009。也有可能是因为`dropout`的原因导致你在深层神经网络中遇到欠拟合的情况。 | ||
| [dropout](http://www.cnblogs.com/tornadomeet/p/3258122.html)在模型训练时随机将激活设置为零(让网络某些隐含层节点的权重不工作),以避免过拟合。这不会发生在验证/测试集的预测中。如果发生了这种情况,你可以移除 `dropout`。如果模型现在出现大规模的过拟合,你可以开始添加小批量的 `dropout`。 |
|
|
||
| #### **Batch Normalization** | ||
| 译者注:这里进一步[解释](http://blog.csdn.net/hjimce/article/details/50413257)一下dropout。 |
|
|
||
| Standardizing the inputs of your model is something that you have definitely heard about if you are into machine learning. Batch normalization takes this a step further. Batch normalization adds a ‘normalization layer’ after each convolutional layer. This allows the model to converge much faster in training and therefore also allows you to use higher learning rates. | ||
| 1、其实Dropout很容易实现,源码只需要几句话就可以搞定了,让某个神经元以概率p,停止工作,其实就是让它的激活值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活值为x1,x2...x1000,我们dropout比率选择0.4,那么这一层神经元经过drop后,x1...x1000神经元其中会有大约400个的值被置为0。 |
|
|
||
| 如果你对机器学习有所了解,你一定听过标准化模型输入。批量归一化加强了这一步。批量归一化在每个卷积层之后添加“归一化层”。这使得模型在训练中收敛得更快,因此也允许你使用更高的学习率。 | ||
|
|
||
| 简单地标准化每个激活层中的权重不起作用。随机梯度下降非常顽固。如果使得其中一个比重非常高,那么下一次训练它就会简单地重复这个过程。通过批量归一化,模型可以学习到它可以每一次都调整所有权重而某一个权重。 |
There was a problem hiding this comment.
模型可以学习到它可以每一次都调整所有权重而某一个权重 ->
模型可以在每次训练中调整所有的权重而非仅仅只是一个权重
|
|
||
| #### ** 四、MNIST 数字识别** | ||
|
|
||
| [MNIST](http://yann.lecun.com/exdb/mnist/)手写数字数据集是机器学习中最着名的数据集之一。数据集也是一个检验我们所学CNN知识的很好的方式。[Kaggle](https://www.kaggle.com/c/digit-recognizer)也承载了MNIST数据集。这段我很快写出的代码,在这个数据集上的准确度为96.8%。 |
|
|
||
| #### ** 四、MNIST 数字识别** | ||
|
|
||
| [MNIST](http://yann.lecun.com/exdb/mnist/)手写数字数据集是机器学习中最着名的数据集之一。数据集也是一个检验我们所学CNN知识的很好的方式。[Kaggle](https://www.kaggle.com/c/digit-recognizer)也承载了MNIST数据集。这段我很快写出的代码,在这个数据集上的准确度为96.8%。 |
|
@sqrthree 一校完成 |
|
@lileizhenshuai 十分感谢,改的很细致,我会一一改正! |
|
@sqrthree 校对认领 |
|
@changkun 妥妥哒 🍻 |
|
|
||
| ## What are convolutions, max pooling and dropout? | ||
| ## 什么是卷积,最大池化(Max pooling)和 dropout? |
There was a problem hiding this comment.
「什么是卷积,最大池化(Max pooling)和 dropout?」=>「什么是卷积、最大池化和 Dropout?」
此处为文章副标题,可以不用说明名词英文
|
|
||
| #### **Convolutions** | ||
| 欢迎来到本系列教程的第三部分的学习!这周我会讲解一些` CNN `的内容并且讨论如何解决`欠拟合`和`过拟合`。 |
There was a problem hiding this comment.
「这周我会讲解一些CNN的内容」=>「这周我会讲一些卷积神经网络(Convolutional Neural Network, CNN)的内容」
直译尽量保持与原文内容一致,首次出现的名词缩写可以考虑按此方式书写
|
|
||
| So what exactly is a convolution? As you might remember from my previous blog entries we basically take a small filter and slide this filter over the whole image. Next, the pixel values of the image are multiplied with the pixel values in the filter. The beauty in using deep learning is that we do not have to think about how these filters should look. Through Stochastic Gradient Descent (SGD) the network is able to learn the optimal filters. The filters are initialized at random and are location-invariant. This means that they can find something everywhere in the image. At the same time the model also learns where in the image it has found this thing. | ||
| #### **一、卷积(Convolutions)** |
There was a problem hiding this comment.
「卷积(Convolutions)」=>「卷积(Convolution)」
名词说明的时候应该用原形,而不是复数,所以 Convolution
|
|
||
| Zero padding is a helpful tool when applying this filters. All this does, is at extra borders of zero pixels around the image. This allows us to also capture the edges of the images when sliding the filter over the image. You might wonder what size the filters should be. Research has shown that smaller filters generally perform better. In this case we use filters of size 3x3. | ||
| 那么究竟什么是卷积呢?你可能还记得我之前的博客,我们使用了一个小的滤波器(filter),并在整个图像上平滑移动这个滤波器。然后,将图像的像素值与滤波器中的像素值相乘。使用深度学习的优雅之处在于我们不必考虑这些滤波器应该是什么样的 —— 神经网络会自动学习并选取最佳的滤波器。通过随机梯度下降(SGD),网络能够自主学习从而达到最优滤波器效果。滤波器被随机初始化,并且位置不变。这意味着他们可以在图像中找到任何物体。同时,该模型还能学习到是在这个图像的哪个位置找到这个物体。 |
|
|
||
| Zero padding is a helpful tool when applying this filters. All this does, is at extra borders of zero pixels around the image. This allows us to also capture the edges of the images when sliding the filter over the image. You might wonder what size the filters should be. Research has shown that smaller filters generally perform better. In this case we use filters of size 3x3. | ||
| 那么究竟什么是卷积呢?你可能还记得我之前的博客,我们使用了一个小的滤波器(filter),并在整个图像上平滑移动这个滤波器。然后,将图像的像素值与滤波器中的像素值相乘。使用深度学习的优雅之处在于我们不必考虑这些滤波器应该是什么样的 —— 神经网络会自动学习并选取最佳的滤波器。通过随机梯度下降(SGD),网络能够自主学习从而达到最优滤波器效果。滤波器被随机初始化,并且位置不变。这意味着他们可以在图像中找到任何物体。同时,该模型还能学习到是在这个图像的哪个位置找到这个物体。 |
There was a problem hiding this comment.
「平滑移动」=>「滑动」
平滑移动就是另一个意思了,CNN中的滤波器滑动stride可以不一定是1,所以滑动更贴近原作者意思,译者可以再斟酌一下
|
|
||
| Standardizing the inputs of your model is something that you have definitely heard about if you are into machine learning. Batch normalization takes this a step further. Batch normalization adds a ‘normalization layer’ after each convolutional layer. This allows the model to converge much faster in training and therefore also allows you to use higher learning rates. | ||
| 译者注:这里进一步[解释](http://blog.csdn.net/hjimce/article/details/50413257)一下 dropout。 |
There was a problem hiding this comment.
理由同上,这个解释是没有必要的,原文作者的一句话解释已经很好了,所以个人觉得应该删掉。翻译不是评注,应该侧重于表达原作者的想法,有额外的读后感可以另开一片文章
|
|
||
| The [MNIST](http://yann.lecun.com/exdb/mnist/) handwritten digits dataset is one of the most famous datasets in machine learning. The dataset also is a great way to experiment with everything we now know about CNNs. [Kaggle ](https://www.kaggle.com/c/digit-recognizer)also hosts the MNIST dataset. This code I quickly wrote is all that is necessary to score 96.8% accuracy on this dataset. | ||
| #### **三、批量归一化(Batch Normalization )** |
There was a problem hiding this comment.
「批量归一化(Batch Normalization)」=>「批标准化(Batch Normalization)」
批标准化也是一个已经很常见的译法,当然这个也看译者偏好,如果此处修改为批标准化,那么后文中也要做相应的修改。译者可以自行斟酌。
|
|
||
| If you liked this posts be sure to recommend it so others can see it. You can also follow this profile to keep up with my process in the Fast AI course. See you there! | ||
| 然而,配备深层 CNN 可以达到 99.7% 的效果。本周我将尝试将 CNN 应用到这个数据集上,希望我在下周可以报告最新的精度值并且讨论我所遇到的问题。 |
There was a problem hiding this comment.
「精度值」=>「准确率」
accuracy 准确率, recall 召回率 这是这些名词的常见译法
|
|
||
|  | ||
| 对于快速AI课程的学习者:请注意教材中使用 “width_zoom_range” 作为数据扩充参数之一。但是,这个选项在 Keras 中不再可用。 |
There was a problem hiding this comment.
对于快速AI课程的学习者 => 对于「Fast AI」课程的学习者
|
|
||
| 如果你喜欢这篇文章,欢迎推荐它以便其他人可以看到它。您还可以按照此配置文件跟上我在快速AI课程中的进度。到时候见! |
There was a problem hiding this comment.
十分感谢!我会仔细你检查指出的问题并做出一定的修改。对于批注的初衷这一点正如尾注所言,考虑之后认为还是应该删去,尽可能与原文保持一致。再次感谢!
|
@sqrthree 根据两位校对的意见修改完毕 |
|
|
||
| ## What are convolutions, max pooling and dropout? | ||
| ## 什么是卷积,最大池化和 Dropout? |
There was a problem hiding this comment.
『卷积,最大池化和 Dropout』=>『卷积、最大池化和 Dropout』
|
|
||
| Data augmentation includes things like randomly rotating the image, zooming in, adding a color filter etc. Data augmentation only happens to the training set and not on the validation/test set. It can be useful to check if you are using too much data augmentation. For example, if you zoom in so much that features of a cat are not visible anymore, than the model is not going to get better from training on these images. Let’s explore some data augmentation! | ||
| 数据增强包括随机旋转图像,放大图像,添加颜色滤波器等等。 |
There was a problem hiding this comment.
『随机旋转图像,放大图像,添加颜色滤波器』=>『随机旋转图像、放大图像、添加颜色滤波器』
| The [MNIST](http://yann.lecun.com/exdb/mnist/) handwritten digits dataset is one of the most famous datasets in machine learning. The dataset also is a great way to experiment with everything we now know about CNNs. [Kaggle ](https://www.kaggle.com/c/digit-recognizer)also hosts the MNIST dataset. This code I quickly wrote is all that is necessary to score 96.8% accuracy on this dataset. | ||
| 简单地标准化每个激活层中的权重不起作用。随机梯度下降非常顽固。如果使得其中一个比重非常高,那么下一次训练它就会简单地重复这个过程。通过批量归一化,模型可以在每次训练中调整所有的权重而非仅仅只是一个权重。 | ||
|
|
||
| #### ** 四、MNIST 数字识别** |

|
@sqrthree 已修改 |
|
已经 merge 啦~ 快快麻溜发布到掘金专栏然后给我发下链接,方便及时添加积分哟。 |
|
@sqrthree 好的,已经发布到专栏,链接如下:https://juejin.im/post/598f25b15188257d8643173d 辛苦啦~ |
issues: #1928