Implementing Regularized Dropout for Neural Networks with PaddlePaddle
实验部分我使用脚本任务进行多卡训练,论文中训练了10000个step,训练结束时模型已经收敛,且达到了论文精度:
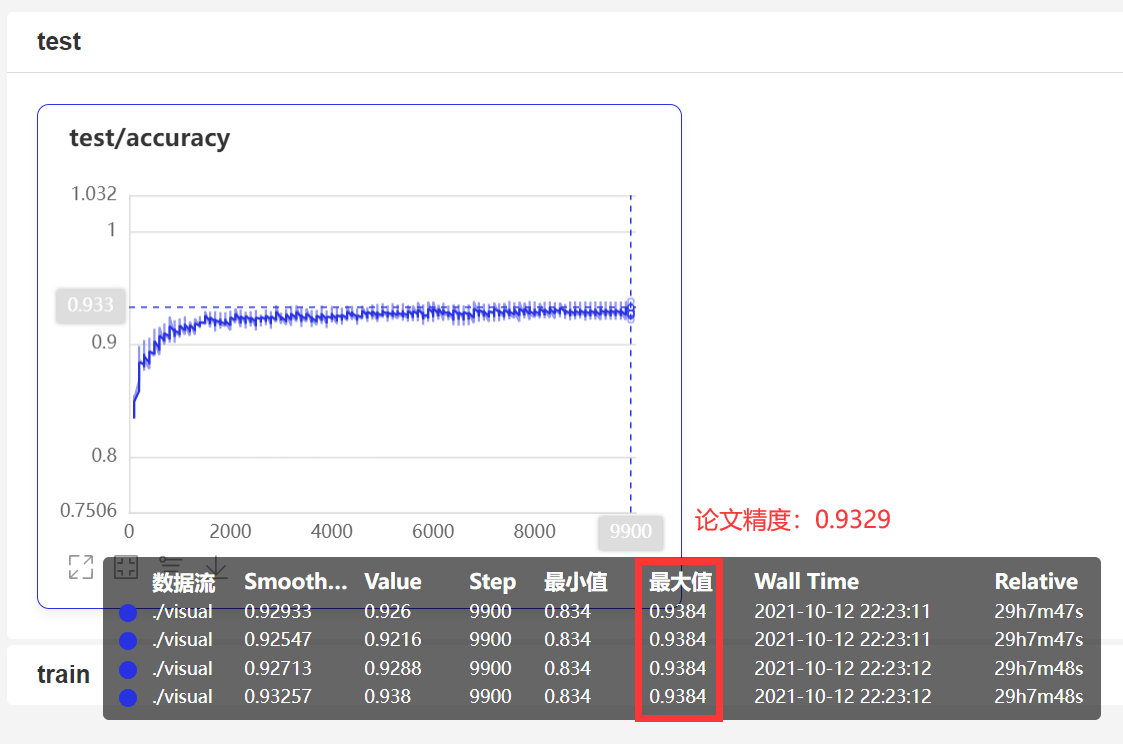
验证模型精度的截图(如果图片无法显示,请前往本项目中的images/log.png查看该图片)
log可视化已上传至服务器,可随时查看:http://180.76.144.223:8040/app/scalar
模型权重已经上传至https://aistudio.baidu.com/aistudio/datasetdetail/105204,并加载到AI Studio项目(R-Drop:摘下SOTA的Dropout正则化策略)中,以便检验精度:
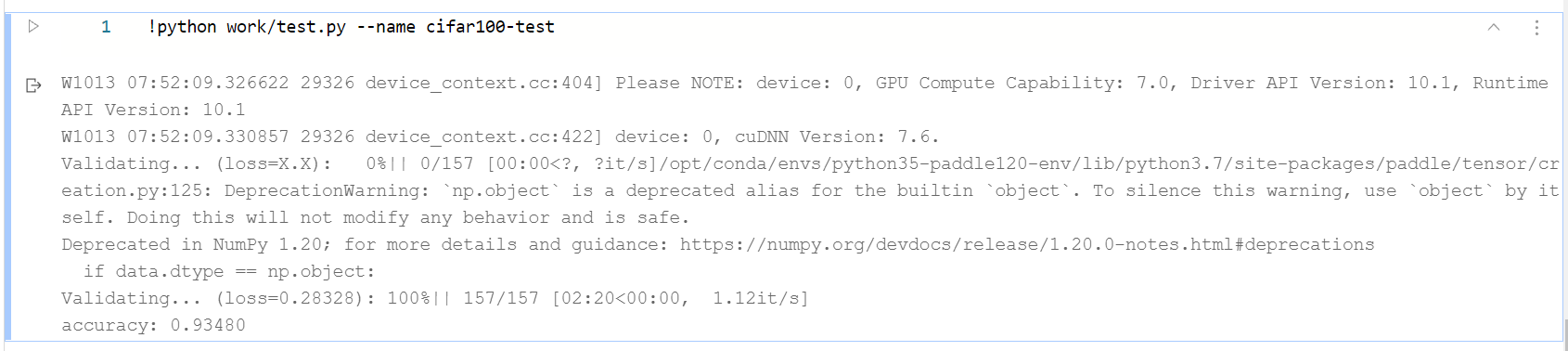
images/test.png查看该图片)
论文《R-Drop: Regularized Dropout for Neural Networks》要求的数据集是CIFAR-100,验收标准是ViT-B_16+RD在CIFAR100的验证集上准确率为93.29%,我们的复现精度为93.44%比论文的精度高0.1个点左右。(脚本任务训练完以后的模型最高精度是93.92%,但是把模型拿下来放在单卡跑的时候,精度有所损失)
R-Drop这篇论文解决了Dropout在训练与预测时输出不一致的问题,论文作者将解决该问题的方法取名为R-drop,这是一种基于dropout的简单而有效的正则化方法,它通过在模型训练中最小化从dropout中采样的任何一对子模型的输出分布的双向KL散度来实现。最核心的代码如下所示:
import paddle
import paddle.nn.functional as F
class kl_loss(paddle.nn.Layer):
def __init__(self):
super(kl_loss, self).__init__()
self.cross_entropy_loss = paddle.nn.CrossEntropyLoss()
def forward(self, p, q, label):
ce_loss = 0.5 * (self.cross_entropy_loss(p, label) + self.cross_entropy_loss(q, label))
kl_loss = self.compute_kl_loss(p, q)
# carefully choose hyper-parameters
loss = ce_loss + 0.3 * kl_loss
return loss
def compute_kl_loss(self, p, q):
p_loss = F.kl_div(F.log_softmax(p, axis=-1), F.softmax(q, axis=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, axis=-1), F.softmax(p, axis=-1), reduction='none')
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
另外,我们在复现论文时整理了一份方法论,希望能对大家有所帮助: