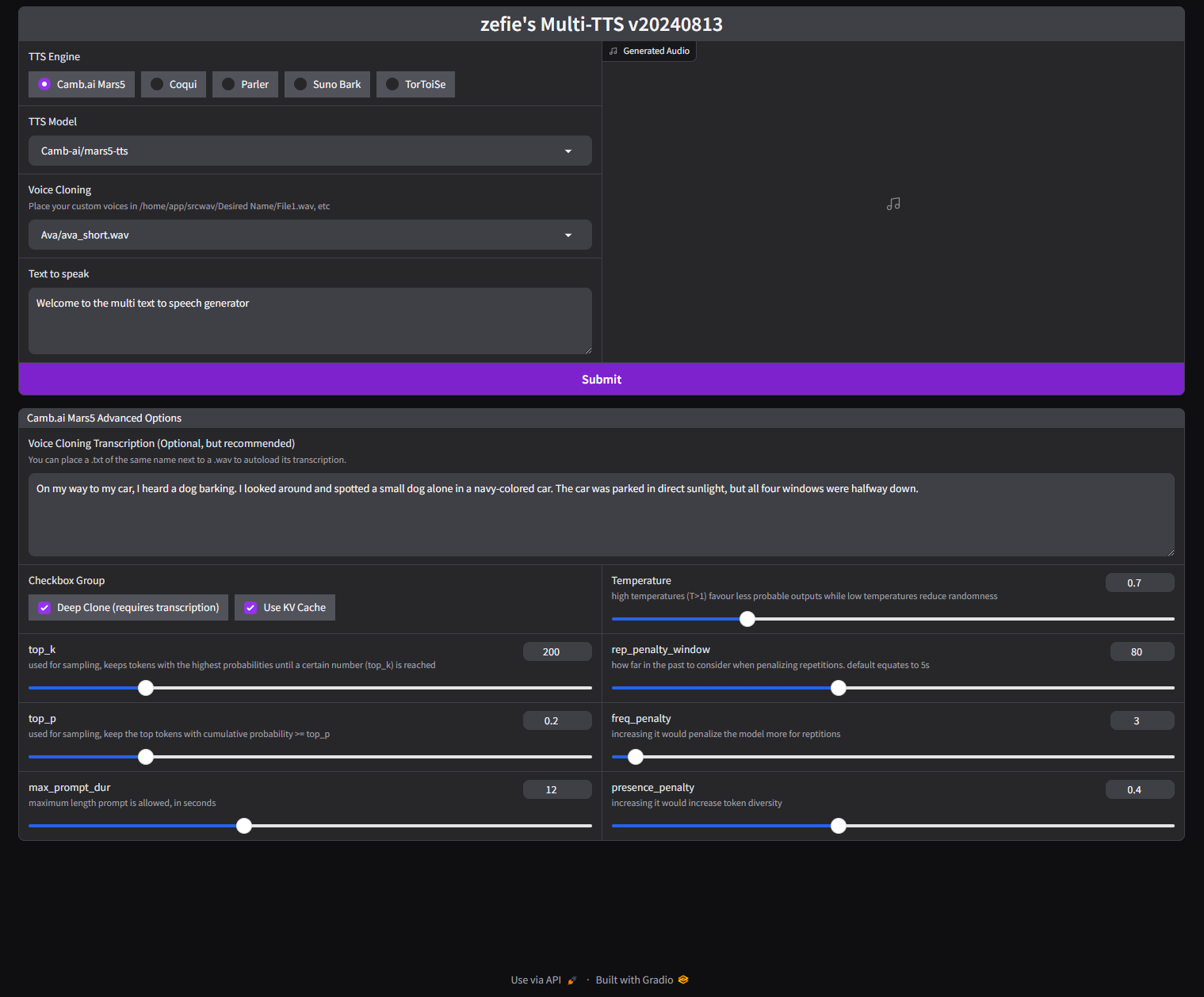
Currently includes Camb.ai Mars5, Coqui, MyShell.ai OpenVoice, Parler, Suno Bark, and TorToiSe.
New 20240817 The application now runs as the user "app" so if you are upgrading, change your paths from /root/.cache to /home/app/.cache
Example usage (CLI):
docker run --rm -it --gpus all -p 7860:7860 -v multitts-cache:/home/app/.cache -v ./srcwav:/home/app/srcwav zefie/multi-tts:latest
Example usage (Docker Compose):
zefie-multitts:
image: zefie/multi-tts:latest
ports:
- 7860:7860
volumes:
- ./srcwav:/home/app/srcwav
- multitts-cache:/home/app/.cache
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [compute, utility]
volumes:
multitts-cache: {} For voice cloning, make a folder under "srcwav" with the name you'd like to appear in the list. Then populate that folder with clean wav files of that person speaking. Example (container path): /home/app/srcwav/Tom/tom1.wav
Play around with your source files until you get the voice you desire. The script will import all wavs in said folder. I recommend 16bit Mono, 22050-48000hz for best results.
git clone https://github.com/zefie/multi-tts.git --depth=1 && cd multi-tts && docker build -t multi-tts:latest .