





Features · Roadmap · Report Bug · Vote New Features · Read Blog · Meet the Team
🏁 Table of Contents
While almost every Huggingface model can be easily deployed to AWS Sagemaker endpoints with a few lines of code, it is often desirous to automate this flow, and have this process track the entire lineage of the model as it goes from training to production.
This project showcases one way of using ZenML pipelines to achieve this:
- Create and version a dataset in a
feature_engineering_pipeline. - Train/Finetune a BERT-based Sentiment Analysis NLP model and push to Huggingface Hub in a
training_pipeline. - Promote this model to
Productionby comparing to previous models in apromotion_pipeline. - Deploy the model at the
ProductionStage to a AWS Sagemaker endpoint with adeployment_pipeline.
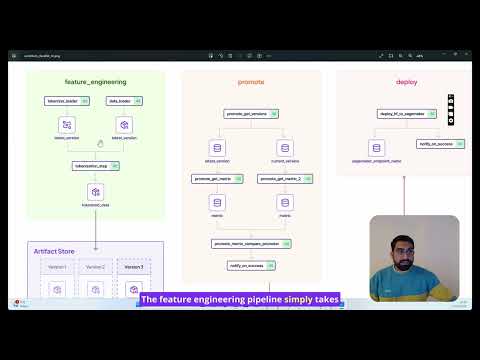
Here is an overview of the entire process:

The above flow is achieved in a repeatable, fully tracked pipeline that is observable across the organization. Let's see how this works.
What to do first? You can start by giving the the project a quick run. The project is ready to be used and can run as-is without any further code changes! You can try it right away by installing ZenML, the needed ZenML integration and then calling the CLI included in the project.
# Clone this repo
git clone git@github.com:zenml-io/zenml-huggingface-sagemaker.git
cd zenml-huggingface-sagemaker
# Set up a Python virtual environment, if you haven't already
python3 -m venv .venv
source .venv/bin/activate
# Install requirements & integrations
# Alternatively see the Makefile for commands to use
make setupAfter this, you should have ZenML and all of the requirements of the project installed locally. Next thing to do is to connect to a deployed ZenML instance. You can create a free trial using ZenML Cloud to get setup quickly.
Once you have your deployed ZenML ready, you can connect to it using:
zenml connect --url YOUR_ZENML_SERVER_URLThis will open up the browser for your to connect to a deployed ZenML!
We now need to register your Huggingface API token to run this demo. This can be found in your settings page. Register this as a ZenML secret with:
zenml secret create huggingface_creds --username=HUGGINGFACE_USERNAME --token=HUGGINGFACE_TOKENTo run this project, you need to create a ZenML Stack with the required components to run the pipelines.
make install-stack
zenml stack hf-sagekamer-localTo deploy to AWS SageMaker, your local AWS client needs the necessary permissions. Ensure that you have been granted SageMaker access on your AWS account. For more information about configuring AWS for programmatic access, refer to the AWS documentation on setting up the AWS CLI.
Please set the appropriate environment variables for your session with the following export commands:
export AWS_ACCESS_KEY_ID=your_access_key_id
export AWS_SECRET_ACCESS_KEY=your_secret_access_key
export AWS_SESSION_TOKEN=your_session_token # if you are using temporary credentialsReplace your_access_key_id, your_secret_access_key, and your_session_token with your actual AWS credentials. These credentials will allow your local AWS client to interact securely with SageMaker and other AWS services.
There are two paths you can take this with the project. You can either use a notebook or run it in scripts. Choose whichever path suits your learning style.
You can also watch a full video walkthrough on YouTube:
# Install jupyter
pip install notebook
# Go to run.ipynb
jupyter notebookIf you're note the notebook type, you can use this README to run the pipelines one by one.
At any time, you can look at the CLI help to see what you can do with the project:
python run.py --helpLet's walk through the process one by one:
The first pipeline is the feature engineering pipeline. This pipeline loads some data from huggingface and uses a base tokenizer to create a tokenized dataset.

Run it as follows:
python run.py --feature-pipeline --no-cacheEach time you run this pipeline, a new base tokenizer and tokenized dataset is produced. In the dashboard, you can click on these artifacts and note their ID's, as they will be used downstream in the training pipeline.
You can watch a YouTube tutorial for this part of the tutorial here.
The training pipeline trains the model on the produced data.

Run it as follows:
python run.py --training-pipeline --num-epochs 1 --train-batch-size 128 --eval-batch-size 12Or if you'd like to use a specific version of data from the feature_engineering_pipeline, you can pass them into the CLI as follows:
python run.py --training-pipeline --num-epochs 2 --train-batch-size 32 --eval-batch-size 32 --dataset-artifact-id 678986c4-11f8-442c-9b9a-3c32ab454e02 --tokenizer-artifact-id 922787cb-151e-484a-8fd0-18f373a488ffNote that if the dataset-artifact-id and tokenizer-artifact-id are not specified, the training pipeline simply appends the feature engineering pipeline to itself to create a fresh dataset.
This will train a model from Huggingface and register a new ZenML model on the Model Control Plane:

Please note the above screens are a cloud-only feature in ZenML Cloud, and
the CLI zenml models list should be used instead for OSS users.
At the end of the pipeline, the model will also be pushed the Huggingface, and a link estabilished between the ZenML Control Plane and the Huggingface model repository.


Notice the linkage of the revision made on Huggingface to the metadata tracked on the ZenML pipeline. This estabilishes lineage.
You can watch a YouTube tutorial for this part of the tutorial here.
You can run the training pipeline a few times to produce many versions of the model. Feel free to edit the parameters accordingly.

When the time is right, you now run the promotion pipeline:
python run.py --promoting-pipeline --no-cacheThis pipeline finds the best model from the last pipelines that were run, and promotes it to production. That simply means its marked as production in the Model Control Plane:

You can watch a YouTube tutorial for this part of the tutorial here.
Finally, when the time is right, its time to deploy the latest Production model with the deploymnet pipeline.

python run.py --deploying-pipelineThis uses the latest Huggingface revision, and deploys it on Sagemaker:
Creating model with name: huggingface-pytorch-inference-2023-11-08-10-33-02-272
Creating endpoint-config with name huggingface-pytorch-inference-2023-11-08-10-33-03-291
Creating endpoint with name huggingface-pytorch-inference-2023-11-08-10-33-03-291```Verify that the endpoint is up:
aws sagemaker list-endpointsYou should see a deployed endpoint to sagemaker.
You can watch a YouTube tutorial for this part of the tutorial here.
cd gradio
python app.py
The demo has two modes: sagemaker and local. If sagemaker is selected, the client pings ZenML, finds the latest Production model, and uses the associated sagemaker endpoint to make the prediction. Otherwise, it just downloads the model and runs it locally. Naturally, the Sagemaker endpoint will usually be faster!
And there you go, you have successfully trained and pushed a model to Huggingface, and deplyoed it to AWS Sagemaker, in a ZenML pipeline. Read more on the ZenML docs
Something didn't work? No problem!
The first point of call should be the ZenML Slack group. Ask your questions about bugs or specific use cases, and someone from the core team will respond. Or, if you prefer, open an issue on this GitHub repo.