
An agile,powerful,standalone,distributed crawler framework.Support spring boot and redisson.
SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油。
If you like this project, please give it a Star. Read detail in English | 日本語 | 한국어 | Русский | Français | Deutsch | Italiano | Español.
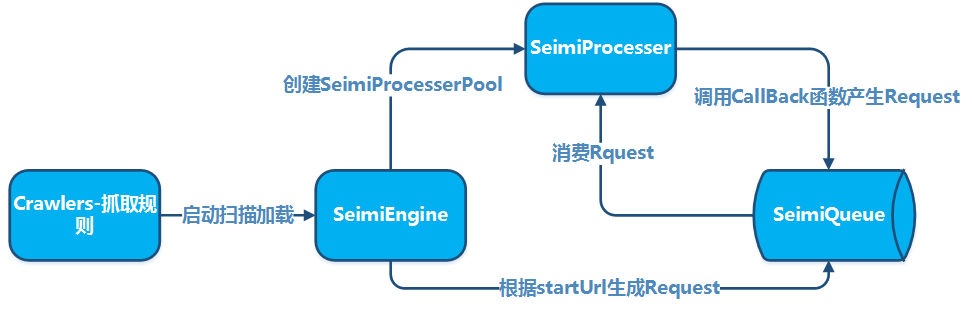
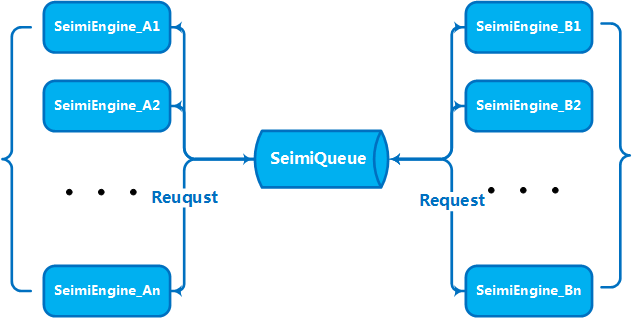
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的Seimi帮你搞定。设计思想上SeimiCrawler受Python的爬虫框架Scrapy启发,同时融合了Java语言本身特点与Spring的特性,并希望在国内更方便且普遍的使用更有效率的XPath解析HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath(独立扩展项目,非jsoup自带),默认解析提取HTML数据工作均使用XPath来完成(当然,数据处理亦可以自行选择其他解析器)。并结合SeimiAgent彻底完美解决复杂动态页面渲染抓取问题。
- 微信订阅号

里面会发布一些使用案例等文章,以及seimi体系相关项目的最新更新动态,后端技术,研发感悟等等。
-
完美支持SpringBoot,demo参考
-
回调函数支持方法引用,设置起来更自然
push(Request.build(s.toString(),Basic::getTitle));
- 非SpringBoot模式全局配置项通过
SeimiConfig进行配置,包括 Redis集群信息,SeimiAgent信息等,SpringBoot模式则通过SpringBoot标准模式配置
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
//config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
SpringBoot模式,在application.properties中配置
seimi.crawler.enabled=true
# 指定要发起start请求的crawler的name
seimi.crawler.names=basic,test
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
#开启分布式队列
seimi.crawler.enable-redisson-queue=true
#自定义bloomFilter预期插入次数,不设置用默认值 ()
#seimi.crawler.bloom-filter-expected-insertions=
#自定义bloomFilter预期的错误率,0.001为1000个允许有一个判断错误的。不设置用默认值(0.001)
#seimi.crawler.bloom-filter-false-probability=
-
分布式队列改用Redisson实现,底层依旧为redis,去重引入BloomFilter以提高空间利用率,一个线上的BloomFilter调参模拟器地址
-
JDK要求 1.8+
- QQ群:
557410934

这个就是给大家自由沟通啦
添加maven依赖(以中央maven库最新版本为准,下仅供参考):
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.4</version>
</dependency>
在包crawlers下添加爬虫规则,例如:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
//do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
然后随便某个包下添加启动Main函数,启动SeimiCrawler:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
以上便是一个最简单的爬虫系统开发流程。
推荐使用spring boot方式来构建项目,这样能借助现有的spring boot生态扩展出很多意想不到的玩法。Spring boot项目打包参考spring boot官网的标准打包方式即可
mvn package
上面可以方便的用来开发或是调试,当然也可以成为生产环境下一种启动方式。但是,为了便于工程化部署与分发,SeimiCrawler提供了专门的打包插件用来对SeimiCrawler工程进行打包,打好的包可以直接分发部署运行了。
pom中添加添加plugin
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.2.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
<!--<configuration>-->
<!-- 默认target目录 -->
<!--<outputDirectory>/some/path</outputDirectory>-->
<!--</configuration>-->
</plugin>
执行mvn clean package即可,打好包目录结构如下:
.
├── bin # 相应的脚本中也有具体启动参数说明介绍,在此不再敖述
│ ├── run.bat #windows下启动脚本
│ └── run.sh #Linux下启动脚本
└── seimi
├── classes #Crawler工程业务类及相关配置文件目录
└── lib #工程依赖包目录
接下来就可以直接用来分发与部署了。
详细请继续参阅maven-seimicrawler-plugin
目前可以参考demo工程中的样例,基本包含了主要的特性用法。更为细致的文档移步SeimiCrawler主页中进一步查看
请参阅 ChangeLog.md
BTW: 如果您觉着这个项目不错,到github上
star一下,我是不介意的 ^_^