ScalableGCN
ScalableGCN是一种由阿里妈妈提出的在大规模图上加速Mini-batch GCN训练速度方法。在Mini-batch GCN中,需要投入的计算力与GCN的层数成指数关系。并且,下层模型的训练频率显著的高于上层。ScalableGCN利用前向计算和反向计算的Cache,在mini-batch之间共享中间层表示的计算结果,同时维护每个顶点上的异步梯度更新的通路。达到在与GCN层数成线性关系的时间内训练GCN模型的目的。
为了获取网络图中每个顶点的embedding,GCN(Graph Convolution Network)的做法是对于每个顶点聚合其邻接顶点的embedding,进而得到更高一阶的顶点embedding。具体地,对于一个阶的GCN模型,定义第k层的embedding为
,其中
为顶点的原始特征。那么
其中是
的邻接顶点。
就是最终图上每个顶点的embedding表示。
和
的应用也被称为图上的卷积操作,不同的模型对于具体的卷积操作有不同的选择。其中,为了更好的权重共享和规范化GCN采用的是:
而GageSage强化了中心顶点特征以及提供了灵活的聚合选择,其中:
对于大规模的图来说,mini-batch的GCN训练对于模型收敛来说是必不可缺的。然而,聚合多层的邻接顶点在计算量上往往是难以接受的,因此GraphSage对于GCN的一个改进就是引入了对邻接顶点的采样。即便如此,Mini-batch GCN所需的计算力仍然是和卷积的阶数成指数关系的。
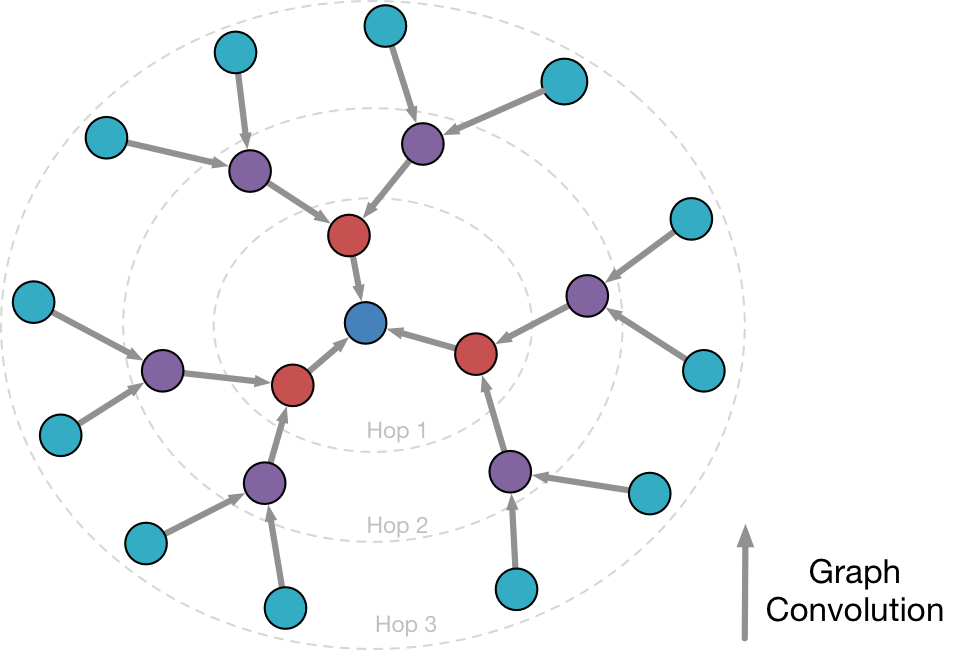
为了在大规模图上降低采样带来的精度损失,我们会需要更宽的邻接顶点采样,例如度为5或者度为10。此时embedding的计算膨胀会更为显著。因此为了实现两到三阶的GCN,我们需要投入两到三个数量级的计算力,而GCN的模型效果增益随着阶数的增加是递减的。高昂的计算力需求增加了模型训练的时间,也制约了GCN模型的实际应用。在这之前,也有一些工作尝试降低GCN的训练时间。FastGCN对一个mini-batch样本集的每阶邻居进行固定采样,使得mini-batch中的所有顶点共享同一个邻接顶点集合,以此将指数级计算时间降低到线性级别。然而对于大规模的稀疏图,共享邻居集合会使得mini-batch中的邻接顶点过于稀疏,进而影响模型的收敛效果。
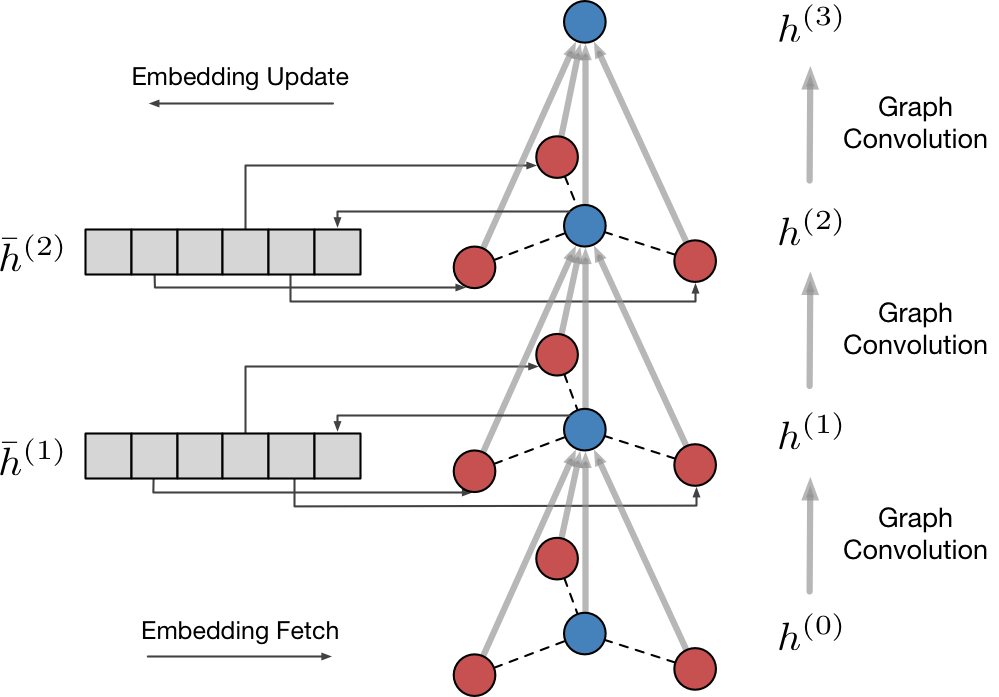
相比起在mini-batch中裁剪和共享采样的方法,我们采取了另一条路径降低GCN的计算量。考虑到邻接顶点的低阶embedding在mini-batch之间被大量的重复引用,我们尝试引入embedding的缓存,在缓存中直接查询邻接顶点(图中红色)的embedding并更新中心顶点(图中蓝色)的embedding。具体地,对于阶GCN模型,开辟存储空间:
,
…
,将mini-batch SGD中各顶点最新的前
阶embedding存储起来。同时,我们修改GCN模型为:
即在汇聚的时候使用缓存中的embedding值,这样一来我们只需计算mini-batch中的样本顶点的卷积结果,无需对扩散后的阶所有邻接顶点进行卷积计算。我们用中心顶点(图中蓝色)的embedding
更新
。
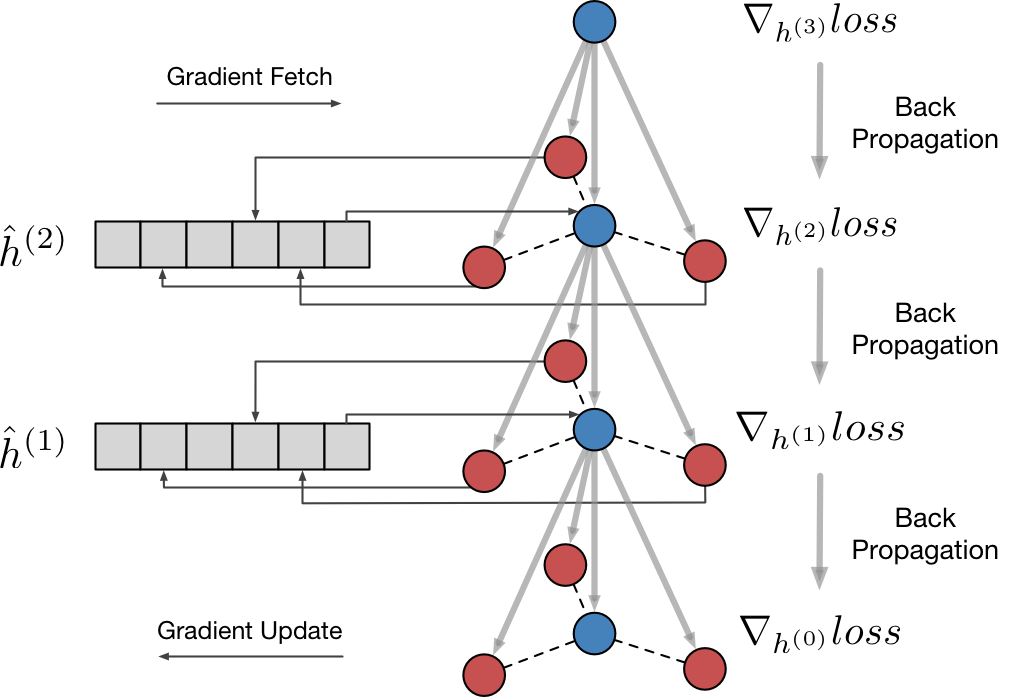
然而,邻接顶点处的梯度无法直接进行Back-Propagation。为了解决这个问题,我们另外开辟存储空间,
…
,将
对
的梯度
追加到
。为了不失灵活性,我们在每个mini-batch后把
更新为
。这里的
可以是平均、累加、指数移动平均等操作。
我们又将作为梯度利用梯度下降算法对
进行更新。注意到而
是顶点
处的累计未消费梯度,这里实际上是在对邻接顶点(图中红色)处的梯度进行延迟的Back-Propagation。在消费后,我们将
重置。
我们在两个开源的数据集Reddi和PPI上验证了我们的工作。由于GraphSAGE的简单和通用性,我们选择其为baseline。并且为了对齐与其论文中的实验结果,我们在共享了GraphSAGE和ScalableGCN代码中的大多数模块,并利用Tensorflow中的Variable存储和
,使用累加作为
算子。我们使用均匀分布来初始化
,并将
初始化为0。对于每阶的卷积操作,我们采样10个邻接顶点。所有的实验均使用512的batch size训练20个epoch。在评估阶段,我们统一维持GraphSAGE的方法进行Inference。以下是选择Mean作为AGG函数的micro-F1 score:
PPI:
| 层数 | 算法 | Micro-F1 |
|---|---|---|
| 1层 | GraphSAGE | 0.47196 |
| 2层 | GraphSAGE | 0.58476 |
| 2层 | ScalableGCN | 0.57746 |
| 3层 | GraphSAGE | 0.63796 |
| 3层 | ScalableGCN | 0.63402 |
Reddit:
| 层数 | 算法 | Micro-F1 |
|---|---|---|
| 1层 | GraphSAGE | 0.91722 |
| 2层 | GraphSAGE | 0.94150 |
| 2层 | ScalableGCN | 0.93843 |
| 3层 | GraphSAGE | 0.94816 |
| 3层 | ScalableGCN | 0.94331 |
可以看到ScalableGCN训练出来模型与GraphSAGE的训练结果相差很小,同时可以取得多层卷积模型的收益。在时间上,以下是8 core的机器上Reddit数据集(23万顶点)每个mini-batch所需的训练时间:
| 每mini-batch时间 / 秒 | ||
|---|---|---|
| 1层 | GraphSAGE | 0.013 |
| 2层 | GraphSAGE | 0.120 |
| 2层 | ScalableGCN | 0.026 |
| 3层 | GraphSAGE | 1.119 |
| 3层 | ScalableGCN | 0.035 |
注意到ScalableGCN的训练时间相对于卷积模型层数来说是线性的。
GCN是目前业界标准的网络图中特征抽取以及表示学习的方法,未来在搜索、广告、推荐等场景中有着广泛的应用。多阶的GCN的支持提供了在图中挖掘多阶关系的能力。ScalableGCN提出了一种快速训练多阶GCN的方法,可以有效的缩短多阶GCN的训练时间,并且适用于大规模的稀疏图。本方法与对采样进行裁剪和共享的方法也并不冲突,可以同时在训练中使用。
[1] Kipf, Thomas N., and Max Welling. "Semi-supervised classification with graph convolutional networks." arXiv preprint arXiv:1609.02907 (2016).
[2] Hamilton, Will, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs." Advances in Neural Information Processing Systems. 2017.
[3] Chen, Jie, Tengfei Ma, and Cao Xiao. "FastGCN: fast learning with graph convolutional networks via importance sampling." arXiv preprint arXiv:1801.10247 (2018).